Если посмотреть на типичную ИТ-инфраструктуру среднего российского бизнеса в 2026 году, обнаруживается удивительная закономерность. Компания на двести-четыреста сотрудников, которая занимается, например, оптовой торговлей промышленной химией или производством упаковки, как правило, тащит на себе не одну, не две и даже не три ключевые цифровые системы, а минимум пять-шесть. И каждая живёт в своём отдельном мире, со своим интерфейсом, своими логами, своей моделью пользователей и своим набором проблем, о которых знает один конкретный человек — обычно тот, кто эту систему когда-то поднимал.
Перечень почти всегда выглядит одинаково. Где-то стоит основной сайт компании — чаще всего это либо WordPress с WooCommerce для приёма заказов, либо самописное приложение на каком-нибудь Next.js или Laravel, развёрнутое на VPS у Timeweb или Selectel. Параллельно у отдела продаж работает Bitrix24, иногда в коробочной версии на собственном Linux-сервере, иногда в облаке — но в обоих случаях через него проходят все сделки, контакты, задачи и часть телефонии. Учётная система — традиционно 1С УТ 12, ну или Бухгалтерия 8.3, или конфигурация ERP, развёрнутая на Windows Server где-нибудь в стойке у провайдера, доступная только через тонкого клиента или через тот самый загадочный OData, который никто из коммерческого отдела никогда не видел. К этому почти неизбежно добавляется AmoCRM — она появляется в момент, когда отдел продаж перерастает возможности базового Bitrix24 или когда руководитель этого отдела имеет опыт работы только с amoCRM и наотрез отказывается переучиваться. Где-то рядом крутится корпоративная почта — почти всегда либо Yandex 360 для бизнеса, либо собственный Mailcow на отдельной виртуалке. Финальным штрихом идёт маркетинговый WordPress или Tilda-сайт для лендингов рекламных кампаний, плюс десяток-другой технических доменов вроде status.company.ru, docs.company.ru и api.company.ru, которые либо работают, либо когда-то работали, и никто уже не помнит, что именно там было.
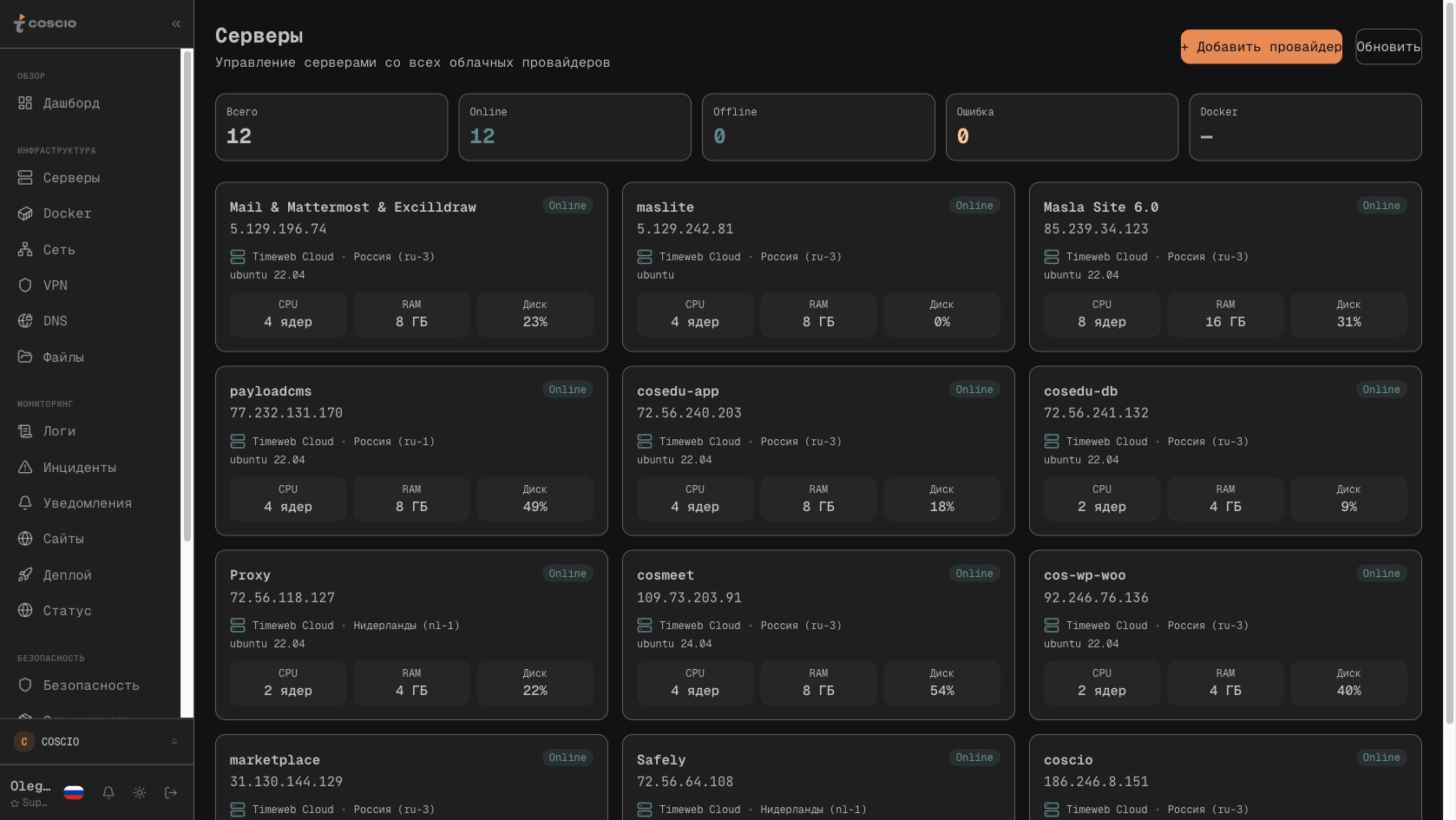
Список серверов в одной панели — каждая строка может скрывать за собой Bitrix24, 1С или WordPress, но видны они здесь одинаково
И вот тут начинается самое интересное. Никто, абсолютно никто в этой компании не имеет полного представления о том, как все эти системы связаны между собой и в каком они состоянии. Финансовый директор знает про 1С, потому что оттуда выгружается отчётность. Коммерческий директор знает про Bitrix24, потому что каждое утро смотрит воронку. Маркетолог знает про WordPress, потому что лично постит туда статьи и собирает лиды. Системный администратор знает про серверы как набор IP-адресов и SSH-доступов, но почти никогда не понимает, какой бизнес-процесс стоит за каждым из них. А если в компании ещё и есть выделенный человек на роль ИТ-директора или ИТ-руководителя, то именно он чаще всего оказывается единственной точкой, где должны сходиться все провода — но в реальности у него для этого нет вообще никакого инструмента. Есть Bitrix-админка с её собственным разделом мониторинга нагрузки. Есть тонкий клиент 1С, в котором что-то можно посмотреть в журнале регистрации. Есть SSH в десять разных машин и десять отдельных вкладок Grafana, если она вообще где-то поднята. Есть WordPress-админка с её собственным разделом Site Health. И ничего общего между всем этим не предусмотрено в принципе.
Идея, что технический руководитель должен иметь возможность видеть бизнес-системы в их совокупности — не для того, чтобы рулить продажами или закрывать сделки, а для того, чтобы понимать общую картину инцидентов и нагрузки, — кажется очевидной, но в российской практике почти не реализована. Потому что классические инструменты ITSM, которые приходят в голову первыми, заточены под другое. Zabbix умеет смотреть метрики сервера, но ничего не знает про сущности Bitrix24. Битрикс знает про сделки и контакты, но не имеет понятия о том, что в этот момент происходит на соседнем сервере с 1С. 1С через OData отдаёт остатки и номенклатуру, но не имеет в принципе никакого способа сообщить миру: «вот сейчас у меня случился сбой синхронизации, обратите внимание». WordPress показывает аптайм только сам про себя. И собирать всё это в один экран приходится либо вручную — открывая десять вкладок и переключаясь между ними, либо строить собственную систему агрегации, которой никто никогда не строит, потому что задача звучит абстрактно, а ресурсов на неё всегда не хватает.
Зачем технический директор, если он именно технический, вообще должен видеть сделки в Bitrix24 или номенклатуру в 1С. Ответ простой — он не должен ими управлять. Управлять сделкой будет менеджер, заводить номенклатуру будет товаровед, согласовывать платёж будет бухгалтер. Но если в какой-то момент сайт компании перестал принимать заказы, и одновременно с этим из 1С пропали несколько свежезаведённых номенклатурных позиций, и в Bitrix24 в это же самое время отвалился вебхук, который должен был создавать сделки из заявок с сайта, — то без единой ленты событий понять, что эти три факта связаны между собой, практически невозможно. Каждый из них в своей системе выглядит как мелкая локальная аномалия. Сайт «иногда тупит». 1С «у девочек что-то не работает». Bitrix24 «странно себя ведёт». А вместе это — один инцидент, у которого, скорее всего, есть одна общая причина, например, упавший сервер баз данных или забитый канал у конкретного провайдера. Без сквозного мониторинга эта причина будет искаться часами, иногда сутками, и в это время бизнес будет терять деньги совершенно реально, в рублях, прямо сейчас.
Подход, на котором построена операционная панель COSCIO, выглядит концептуально достаточно просто. Все события от всех источников приводятся к единому формату и пишутся в одну общую таблицу — log_entries. Источников ровно пять, и каждый имеет свой типовой набор полей. Серверные события собираются по SSH через выгрузку journalctl с заданной периодичностью. Docker-события собираются с тех же серверов отдельно — здесь интересны не системные журналы хоста, а именно жизнь контейнеров: запуски, остановки, OOM-killer, перезапуски по unhealthy-статусу. Bitrix24 опрашивается через свой REST API с использованием входящего вебхука, который заводится прямо в админке портала. 1С опрашивается через OData, который, в отличие от Bitrix, требует не вебхука, а классической HTTP Basic-аутентификации поверх обязательного TLS. И, наконец, событиями типа app помечаются собственные операции платформы — старты воркеров, перезагрузки, плановые отключения, всё то, что важно различать с уровня самого приложения, а не с уровня системы.
Сбор разнесён по cron-расписанию таким образом, чтобы не упираться в лимиты сторонних API и не создавать параллельных нагрузок на одни и те же серверы. Серверные журналы выгружаются каждые пятнадцать минут. Docker-события — каждый час, потому что между собой контейнеры синхронизируются достаточно быстро и более частое сканирование избыточно. Bitrix24 опрашивается четыре раза в час — на пятой, двадцатой, тридцать пятой и пятидесятой минутах, что даёт примерно пятнадцатиминутный интервал отставания при гарантированной нагрузке на портал. 1С через OData опрашивается так же четыре раза в час, но со сдвигом — на десятой, двадцать пятой, сороковой и пятьдесят пятой минутах, чтобы выгрузка не пересекалась с Bitrix-выгрузкой и нагрузка распределялась равномерно. И раз в сутки, в четыре часа утра, по таблице log_entries проходит cleanup, удаляя всё, что старше тридцати дней — это значение задаётся переменной LOG_RETENTION_DAYS и при необходимости подкручивается. Тридцать дней — компромисс между объёмом базы и глубиной ретроспективного анализа: обычно этого хватает, чтобы разобрать любой свежий инцидент, а более длительная история анализируется уже по выгрузкам.
Раздел Логи показывает события всех пяти источников в единой ленте — server, docker, bitrix24, onec, app
Важная деталь, которая определяет вообще всю архитектуру таких систем — это то, как хранятся доступы к внешним сервисам. Здесь невозможно идти на компромиссы. Учётка Bitrix24 — это полный доступ ко всем сделкам, контактам и финансовой переписке. Учётка 1С — это, по сути, ключ ко всей коммерческой и складской информации компании. Учётка WordPress с правами публикации — это возможность опубликовать что угодно на главной странице сайта. Если эти креденшелы лежат в коде или в каком-нибудь .env-файле, который попадает в репозиторий, в случае утечки последствия будут катастрофическими. Поэтому в COSCIO принят принцип, который пора уже считать стандартом для подобных платформ. Все интеграции хранятся в таблице integrations, в разрезе конкретного рабочего пространства, с уникальным ограничением на пару organizationId плюс тип интеграции — то есть в одном рабочем пространстве не может одновременно жить две интеграции с Bitrix24 или две с 1С. Сами учётные данные хранятся в JSON-поле credentials, но не в открытом виде, а зашифрованы по AES-256-GCM. Ключ шифрования и соль для деривации лежат в .env платформы в переменных DB_ENCRYPTION_KEY и DB_ENCRYPTION_SALT, и из них через scrypt получается рабочий ключ, который кэшируется в памяти процесса. Если кто-то получит дамп базы данных без доступа к .env приложения — расшифровать креденшелы он не сможет. Это тот минимум, на котором имеет смысл строить операционную панель уровня бизнеса, и без него любые разговоры о «корпоративной готовности» бессмысленны.
Когда я перестал верить в раздельный мониторинг
Лучший способ объяснить, зачем вообще нужна вся эта затея, — это разобрать пару типичных сценариев. Первый сценарий — самый болезненный. У компании падает сайт. Не в смысле «совсем не открывается», а в смысле «через раз отдаёт пятисотую ошибку или висит по двадцать секунд». Публичная страница статуса, которая собирается на основе данных Site Monitor — отдельного механизма, проверяющего внешнюю доступность сайтов с заданной периодичностью, — переходит в жёлтый цвет. Это означает не полную недоступность, а деградацию: ответ есть, но он либо медленный, либо нестабильный, либо приходит с ошибкой. Одновременно с этим в системе создаётся инцидент — автоматически, по правилу, которое привязано к падению ниже определённого SLA. И вот тут начинается то, ради чего вообще существует единая лента событий.
Если открыть страницу инцидента и развернуть блок с автоматическим разбором, ИИ-анализатор поднимает свежие записи из log_entries за окно, скажем, в плюс-минус пятнадцать минут вокруг времени деградации. И обнаруживает, что в это же самое окно у источника onec — то есть у 1С через OData — пошла серия таймаутов. Каждые пятнадцать минут плановый опрос пытался подтянуть номенклатуру и контрагентов, получал ошибку Connection timeout и писал об этом в общую таблицу. Это значит, что синхронизация номенклатуры с сайта в 1С тоже пропустила несколько циклов. И тогда уже становится понятно, куда копать. Может быть, упал сетевой канал между двумя серверами. Может быть, виртуалка с 1С перегружена и не справляется с входящими запросами. Может быть, на стороне 1С идёт массовое перепроведение документов, которое блокирует все таблицы и тормозит OData. Но самое главное — без единой ленты эта корреляция вообще не возникла бы. Системный администратор увидел бы тормоза сайта и пошёл бы смотреть его логи и метрики веб-сервера. Не нашёл бы там ничего критичного, кроме увеличившегося времени ответа на запросы товаров, и через пару часов закрыл бы заявку с пометкой «нагрузка стабилизировалась». А реальная причина — отвалившаяся синхронизация с 1С — так бы и осталась в тени. И на следующий день, через неделю, через месяц это случилось бы снова.
Второй сценарий — про отдельный, очень болезненный для всех, кто работает с WooCommerce, класс инцидентов. Заказ из интернет-магазина не дошёл до 1С. Покупатель что-то купил, оплата прошла, заказ зафиксировался в WooCommerce — но в 1С его нет. Кладовщик не знает, что нужно собирать. Бухгалтер не понимает, на что выставлять закрывающие документы. Менеджер по продажам через два дня видит запись «отгрузка не подтверждена» и идёт разбираться. И начинается классическая беготня — где этот заказ потерялся. В WordPress есть, в Bitrix24 есть в виде сделки, в 1С нет. Если у каждой из этих систем свой собственный журнал и нет ни одного места, где можно было бы поискать по идентификатору заказа сразу везде, поиск превращается в детектив. Если же все события собраны в общую таблицу log_entries, и при коллекторе WooCommerce, и при коллекторе Bitrix, и при попытках синхронизации с 1С в записи попадает orderId — то ровно одна выборка по этому идентификатору отдаёт всю цепочку событий с временными метками. Видно, что заказ появился в WooCommerce в 14:32:11, что в 14:35:08 коллектор Bitrix создал по нему сделку, что в 14:37:15 коллектор 1С попытался передать его в учётную систему и получил ошибку «Контрагент не найден». Расследование, которое раньше занимало полдня и обычно заканчивалось ничем, теперь занимает три минуты. И сразу понятно, что нужно делать — поправить логику автоматического создания контрагента, добавить обработку ситуации с физлицом-разовым покупателем, что угодно.
Третий сценарий — самый коварный, потому что в нём система внешне работает нормально. Bitrix24 принимает вебхук от сайта, отвечает 500. Сайт честно фиксирует у себя в логе, что попытка отправки не удалась, и через какое-то время делает повторную попытку. Иногда удачно, иногда нет. С точки зрения пользователя ничего страшного не происходит — заявки оформляются, заказы принимаются. С точки зрения коммерческого директора всё в порядке — сделки приходят. Но если посмотреть в общую ленту log_entries и отфильтровать по источнику bitrix24 за последнюю неделю, можно увидеть, что доля пятисотых ответов на конкретный вебхук выросла с привычных нуля до пяти процентов. Это аномалия. И в COSCIO такая аномалия обнаруживается не глазами, а правилом — настройкой алерта, который создаёт инцидент, как только частота определённой ошибки превышает заданный порог. Инцидент попадает в общий канал уведомлений, прилетает в Telegram-бот, светится в шторке нотификаций — и проблема, которая в традиционной разрозненной архитектуре оставалась бы незамеченной до момента, когда отвалится уже не пять процентов, а половина вебхуков, решается в зародыше.
Публичная страница статуса показывает не только сайты, но и состояние подключённых бизнес-систем — Bitrix24, 1С, WordPress оказываются равноправными гражданами этого экрана
При этом — и тут важно очень чётко обозначить позицию — COSCIO принципиально не пытается стать ни CRM, ни ERP, ни заменой WordPress-админке. В платформе нет редактирования сделки Bitrix24, нет перепроведения документов 1С, нет публикации статьи на WordPress. Эти задачи остаются в родных интерфейсах соответствующих систем, и любая попытка их перетащить в операционную панель была бы вредной — потому что воспроизвести в чужом интерфейсе всю логику работы менеджера по продажам или товароведа невозможно, а суррогат был бы хуже оригинала. Идея COSCIO принципиально другая. Это не «единый интерфейс для всех бизнес-систем», это «единая лента событий и состояний от всех бизнес-систем для технического руководителя». Сделки видны как контекст, а не как объекты управления. Номенклатура видна как поток данных, а не как редактируемый справочник. WordPress-посты видны как метрика активности, а не как контент-план. И ровно это и нужно человеку, который отвечает за работоспособность всего стека: знать, что происходит, понимать связь между событиями в разных системах, видеть инциденты в момент их возникновения, а не через сутки. Управлять же контентом, заказами или сделками будут те, кому это положено, в их родных приложениях, к которым они привыкли и в которых у них настроены все права, все шаблоны, все привычные операции.
Архитектура подключения 1С заслуживает отдельного объяснения, потому что это, пожалуй, самая нестандартная и самая болезненная часть всей затеи. Дело в том, что 1С в её типовом представлении — это не сетевой сервис в современном смысле слова. Это многослойное приложение с собственным сервером, собственной СУБД (или с какой-то внешней, обычно MS SQL или PostgreSQL), собственным протоколом обмена с клиентами и весьма скромным набором штатных способов выпустить наружу данные. Чаще всего наружу выпускают либо CommerceML-обмен через файловую систему, либо HTTP-сервисы, написанные руками 1С-программиста, либо OData, который доступен в современных конфигурациях из коробки. Именно последний вариант и используется в COSCIO для подключения 1С УТ 12 — и не случайно.
OData в 1С — это REST-интерфейс ко всей метаданным конфигурации. По адресу вида `https://server/имя_базы/odata/standard.odata/` можно получить полный список сущностей, доступных через этот протокол: все справочники, документы, регистры сведений, регистры накоплений, планы счетов и так далее. Каждая сущность доступна по своему URL, поддерживает фильтрацию через параметр `$filter`, проекцию полей через `$select`, разбивку на страницы через `$top` и `$skip`. Это означает, что можно подключиться к 1С и получить, скажем, список номенклатуры с конкретными полями за один HTTP-запрос, не открывая ни тонкий клиент, ни конфигуратор, ни даже браузер. Аутентификация — Basic, то есть логин и пароль передаются в заголовке Authorization в виде base64. Это, с одной стороны, простота — никаких токенов, никаких OAuth-танцев. С другой стороны, абсолютно обязательное требование — TLS. Использование OData 1С по обычному HTTP — это автоматическая утечка пароля пользователя 1С в любом промежуточном узле сети. Никаких компромиссов: только HTTPS, либо подключения нет вообще. В COSCIO эта проверка делается на уровне валидации интеграции — попытка добавить 1С с URL по протоколу http отклоняется.
Конкретно из 1С УТ 12 в COSCIO собирается несколько ключевых сущностей. Номенклатура — потому что именно она чаще всего синхронизируется с сайтом, и расхождения в её составе всплывают на сайте мгновенно. Контрагенты — потому что новые клиенты постоянно приходят из разных источников (с сайта, из CRM, из обработки бумажных документов), и понимание потока их появления важно для оценки нагрузки. Остатки — потому что это критическая для торговли информация, расхождения в которой между складом и сайтом — самая массовая жалоба в любом интернет-магазине. Каждая выгрузка превращается в серию записей в log_entries с источником onec и метаданными о количестве обработанных объектов, времени запроса, кодом ответа. Если что-то пошло не так — таймаут, 401 (неверные креденшелы), 500 (ошибка на стороне 1С) — это сразу видно в общей ленте и в специализированном виджете на странице 1С-интеграции.
Подключение WordPress устроено принципиально иначе, чем 1С, потому что у WordPress есть продуманный REST API из коробки, и обмен с ним выглядит существенно более современно. Главная особенность — это Application Passwords, отдельный механизм аутентификации, появившийся в WordPress 5.6 и с тех пор ставший стандартом для машинных интеграций. Идея в том, что для подключения внешнего сервиса не используется обычный пользовательский пароль (это было бы и небезопасно, и неудобно — менять пароль пришлось бы синхронно везде). Вместо этого администратор WordPress заходит в профиль конкретного пользователя, генерирует Application Password — длинную случайную строку, привязанную к имени приложения, — и именно эту строку отдаёт во внешнюю систему. У такого пароля можно отозвать действие в любой момент, не трогая основной пароль пользователя, и можно завести несколько разных Application Passwords для разных приложений с понятными именами, чтобы потом было видно, кто и когда подключился.
В COSCIO модель WordPressSite хранит URL сайта, имя пользователя и Application Password — последний шифруется тем же AES-256-GCM, что и все остальные креденшелы. По REST API доступно практически всё, что есть в админке: посты, страницы, медиафайлы, пользователи, комментарии, категории, теги, а если на сайте установлен WooCommerce — то ещё и его сущности: заказы, товары, клиенты, налоги, способы доставки. Это даёт возможность не просто следить за работоспособностью сайта (для этого достаточно Site Monitor с его периодической проверкой доступности и времени ответа), но и отслеживать содержательные события — новые опубликованные посты, новые комментарии, новые заказы. Каждое такое событие тоже попадает в log_entries, и снова все становится видно в общей ленте. И снова возникает та самая корреляция, ради которой все затевалось: если резко выросло количество комментариев — это, скорее всего, либо успешная рассылка, либо спам-атака, и в обоих случаях полезно знать об этом сразу. Если упала частота новых заказов до нуля при работающем сайте — что-то сломалось в платёжной интеграции, и это важно увидеть до того, как об этом доложит коммерческий директор на утренней планёрке.
Когда сводить пять источников в один экран становится не роскошью, а гигиеной
Диалог добавления интеграции — на этом этапе вводятся учётные данные, которые тут же шифруются перед записью в БД
Дашборд COSCIO построен таким образом, чтобы технический руководитель открыл его утром, бросил один взгляд и сразу понял, нужно ли куда-то бежать или можно спокойно идти пить кофе. Главный экран показывает агрегированную сводку: количество активных серверов и их состояние, количество открытых инцидентов, общее число событий за последние сутки в разбивке по источникам, ключевые метрики Docker-контейнеров, последние действия пользователей, рекомендации от AI-аналитики. Раздел Серверы показывает плоский список со статусом каждого сервера и быстрой ссылкой на детальную страницу с тремя главными вкладками — обзор, терминал и логи. Логи на странице сервера отфильтрованы именно по этому серверу, что позволяет быстро посмотреть, что происходило на конкретной машине за последний день. На странице Bitrix-интеграции, помимо технических метрик подключения, есть секция CRM с лентой свежих событий — созданных сделок, изменений в воронке, новых задач. На странице 1С-интеграции — аналогичная картина с потоком обновлений номенклатуры и контрагентов. На странице WordPress — лента публикаций и заказов. Везде используется один и тот же подход к отображению событий, потому что они хранятся в одной таблице с одной схемой.
Раздел Логи — это, пожалуй, самый используемый инструмент во всей системе, и устроен он специально так, чтобы быть удобным для свободного поиска. Сверху — фильтры по источнику (все пять опций), по уровню (info, warning, error, debug, fatal), по серверу, по диапазону дат, по полнотекстовому поиску в сообщении и метаданных. Под фильтрами — таблица событий с пагинацией, отсортированная по убыванию времени. Каждая строка раскрывается, показывая полные метаданные события — JSON-объект с произвольной структурой, специфичной для источника. Сбоку — небольшая статистика: распределение событий по источникам и уровням за выбранный период, помогающая увидеть аномалии вроде «вчера было пять ошибок 1С, сегодня уже сорок». API сделан публичным — GET /api/logs принимает все те же фильтры в query-параметрах и отдаёт JSON, что позволяет встроить эти данные куда угодно: в дашборд Grafana, в скрипт ночного отчёта, в Telegram-бот с командой «покажи последние ошибки за час».
Сайт Монитор, или Site Monitor — это не часть единой ленты логов в строгом смысле, а отдельный механизм, проверяющий внешнюю доступность сайтов. Но он тесно связан с общей картиной, потому что результаты его проверок тоже превращаются в события — в инциденты, если падает доступность, и в записи о восстановлении, когда сайт возвращается в норму. Что именно проверяет Site Monitor: HTTP-доступность по заданному URL с настраиваемым ожидаемым кодом ответа, валидность SSL-сертификата и срок его действия (предупреждения за 30 и за 7 дней до истечения), время ответа, наличие заданного текста в теле ответа (для проверки, что страница действительно отдаёт ожидаемый контент, а не заглушку CDN). И — важная деталь — он умеет проверять не только основной маркетинговый сайт, но и веб-морду Bitrix24-портала, и веб-морду WordPress-сайта, и любые другие технические домены. То есть страница Статус, которая публикуется наружу, оказывается универсальным зеркалом состояния всех веб-сервисов компании, а не только её основного сайта. Bitrix24-портал, который многие воспринимают как «приложение, а не сайт», на этой странице оказывается равноправным гражданином, и его падение видно сразу же — а раньше об этом узнавали только когда менеджеры начинали жаловаться, что не могут зайти в свою воронку.
Алертинг устроен так, чтобы не превращать единое окно в свалку ненужных нотификаций. Это, кстати, отдельная большая тема — потому что любая система мониторинга, в которой алерты летят на каждое чихание, через две недели перестаёт читаться вообще. Пользователь привыкает игнорировать оранжевые иконки, и в нужный момент пропускает реально важное сообщение. В COSCIO алерты идут через несколько каналов одновременно: внутренняя шторка уведомлений в шапке приложения с непрочитанными событиями, Telegram-бот (для тех, кто настроил Telegram-интеграцию), email через настроенный SMTP, SMS через sms.ru, push-уведомления через VK MAX. И всё это настраивается по правилам: какой тип события, какой уровень, какой источник, в какой канал. То есть критические инциденты с падением серверов летят в Telegram немедленно, мелкие предупреждения о высокой загрузке CPU копятся внутри платформы и проявляются раз в день в общем дайджесте, а спам-комментарии в WordPress вообще не вызывают никаких внешних уведомлений и просто пишутся в лог для последующего анализа.
Стоит отдельно сказать про корреляцию событий, потому что это то место, где сходство COSCIO с классическими SIEM-системами заканчивается, и начинается её собственная специфика. Классический SIEM ориентирован на безопасность и пытается выявлять атаки на основе паттернов. Операционная панель ИТ-директора заточена под другую задачу — она пытается выявлять связи между бизнес-инцидентами и техническими событиями. Например, она видит, что в одно и то же пятнадцатиминутное окно произошло три события: упал ответ на главной странице сайта, пошли таймауты в OData-запросах к 1С, и в Bitrix24 на эти же 15 минут перестали приходить новые сделки. Каждое из этих событий по отдельности — мелочь. Вместе — это явный паттерн «упал общий канал между офисом и хостингом», и AI-анализатор сразу подсказывает направление поиска. Без агрегации событий из всех пяти источников эта связь не возникает в принципе, и опытный системный администратор может потратить полдня, прыгая между разными вкладками.
Безопасность хранения данных, как уже говорилось, — это краеугольный камень. Но кроме шифрования креденшелов на уровне базы данных, есть ещё несколько важных моментов, которые часто упускают авторы похожих решений. Во-первых, разделение прав внутри платформы: один пользователь рабочего пространства видит логи, другой видит только страницу статуса, третий имеет полный доступ ко всем настройкам интеграций. Во-вторых, аудит действий — кто и когда добавил, изменил или удалил интеграцию, кто посмотрел какие данные. В-третьих, изоляция между рабочими пространствами на уровне организации: даже если у одного пользователя есть доступ к двум разным workspace, данные одной организации никаким образом не попадают в выборки другой — это обеспечивается на уровне Prisma-запросов через обязательную фильтрацию по organizationId. В-четвертых, ротация ключей шифрования — это пока ручная процедура, но архитектура её предусматривает: при смене DB_ENCRYPTION_KEY все existing записи можно перешифровать в фоновом режиме без простоя.
Multi-tenancy в этой архитектуре — не маркетинговое слово, а конкретное техническое решение. Каждый клиент платформы получает собственное рабочее пространство, в котором живут его серверы, его интеграции, его пользователи, его логи. Никакой пересекаемости данных нет в принципе. При этом одна инсталляция COSCIO способна обслуживать произвольное количество рабочих пространств, что важно для агентств и аутсорсинговых компаний, которые управляют инфраструктурой нескольких клиентов и которым нужно быстро переключаться между ними, не теряя контекста. Переключение реализовано через специальный switcher в нижней части бокового меню — клик, и вся панель показывает уже данные другого клиента. Подписка при этом своя у каждого workspace, и тарификация ведётся независимо.
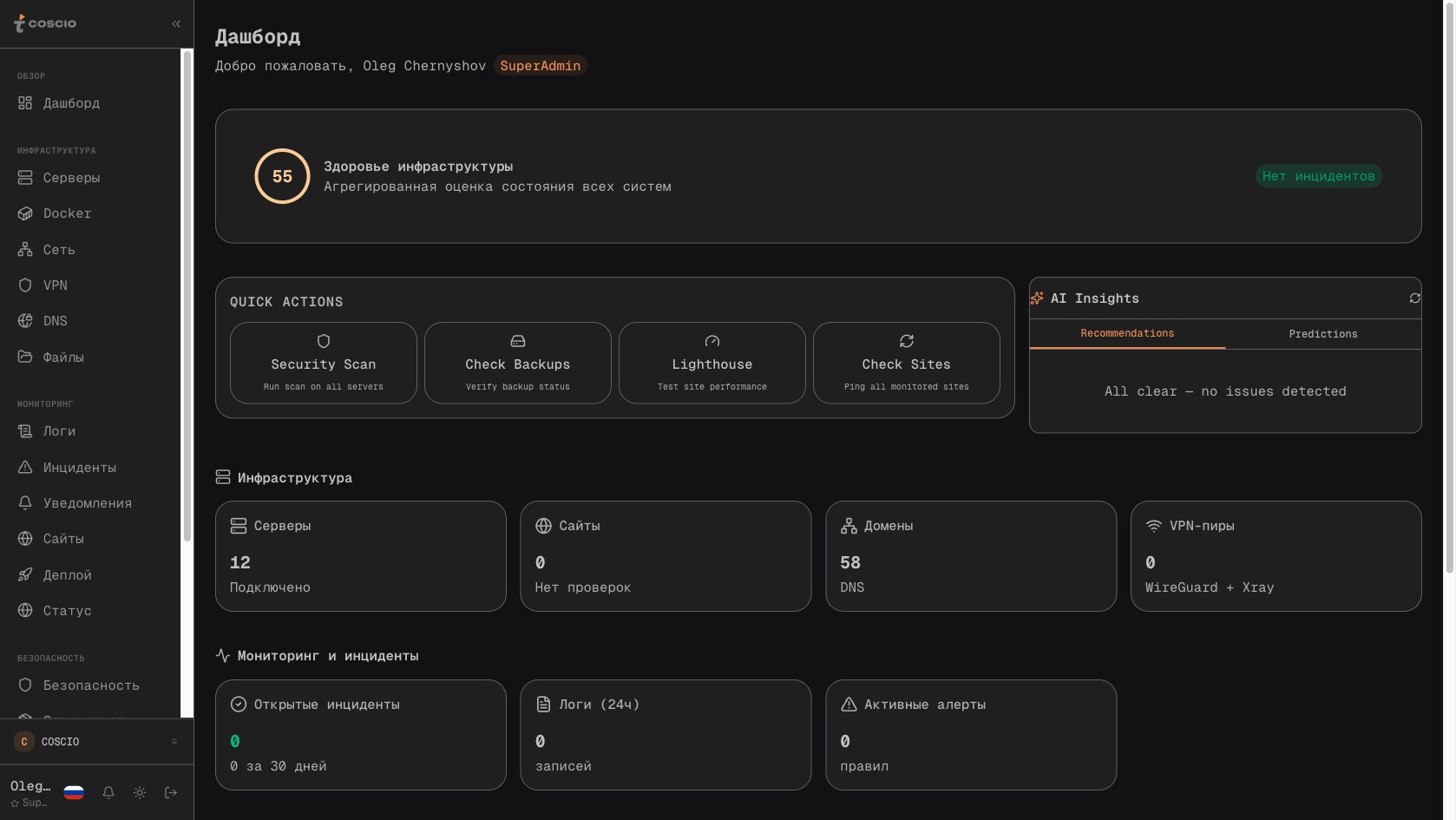
Главный дашборд агрегирует данные всех подключённых систем — серверы, инциденты, активность за сутки, рекомендации AI
И ещё одно важное архитектурное замечание — про то, почему COSCIO построен именно как операционная панель технического руководителя, а не как «единая платформа для всего бизнеса». Соблазн расширить функциональность всегда велик. Можно было бы добавить редактирование сделок Bitrix24 прямо в COSCIO. Можно было бы дать возможность создавать документы в 1С через тот же OData. Можно было бы встроить WYSIWYG-редактор для постов WordPress. И каждый раз, рассматривая такие предложения, приходится возвращаться к исходной идее: COSCIO существует для того, чтобы дать одному человеку — техническому директору — целостную картину работы всех инфраструктурных и интеграционных систем. Как только в платформу начинают добавлять функции, которые дублируют родные интерфейсы бизнес-систем, она перестаёт быть инструментом и начинает быть плохой копией. Поэтому в COSCIO принципиально нет редактирования сделок, документов или постов — только наблюдение за их жизненным циклом. Это не ограничение, это решение. И именно оно позволяет платформе оставаться полезной, а не превращаться в очередной костыль, который пытается заменить всё и не заменяет ничего.
Перспективы развития, если смотреть в среднесрочное окно — год-два — связаны не с добавлением новых источников ради количества, а с углублением аналитики по уже подключённым. AI-анализатор инцидентов уже сейчас умеет искать корреляции в событиях. Логическое продолжение — научить его строить причинно-следственные цепочки на основе исторических данных. Условно говоря, обнаружить, что в последние три месяца каждый раз, когда нагрузка на 1С-сервер превышала определённый порог, через 20-30 минут начинала деградировать веб-морда сайта, и автоматически предупреждать об этом ещё до того, как сайт реально упадёт. Это уже не просто корреляция, это предиктивная аналитика — и для неё нужна именно длинная история событий из всех источников, собранная в одном месте, с одной схемой, с одним временем синхронизации. Что, собственно, и есть log_entries.
Технические руководители российского среднего бизнеса в массе своей живут в режиме постоянного тушения пожаров. Каждый день — десятки переключений между админками, чатами, тонкими клиентами, SSH-сессиями, дашбордами. И в этом потоке очень сложно поддерживать ту самую целостную картину работы инфраструктуры, без которой невозможно ни планировать развитие, ни системно улучшать надёжность, ни даже спокойно уйти в отпуск. Идея единой операционной панели — не новая, она витает в воздухе давно. Но её практическая реализация требует, чтобы кто-то взял на себя труд привести события совершенно разных систем — серверов, CRM, ERP, контент-платформ — к единому формату, к единой базе, к единой временной шкале, к единому интерфейсу поиска и фильтрации. Без этого все разговоры о «360-градусном обзоре» остаются разговорами. С этим — появляется реально работающий инструмент, в котором ИТ-директор перестаёт быть человеком с десятью вкладками и становится человеком с одним окном, в котором он видит всё, что ему нужно видеть, и не видит ничего лишнего. И, кажется, именно в этой точке заканчивается эпоха разрозненного мониторинга и начинается что-то другое.