coscio/blog
From practice
Customer cases, engineering deep-dives, releases, guides. No marketing fluff.
updated regularly
› filter10 posts
БезопасностьMarch 14, 202624 min
Безопасность инфраструктуры в едином портале: сканирование зависимостей, мониторинг угроз, реагирование на брут-форс и интеграция с SIEM
Read
БезопасностьMarch 14, 202621 min
Просроченные SSL — невидимый источник даунтайма: как автоматизировать контроль сертификатов через единый портал инфраструктуры
Read
DevOpsMarch 14, 202624 min
Мультиоблачная инфраструктура для среднего бизнеса: когда оправдан подход, как выбирать провайдеров и чем управлять из единой панели
Read
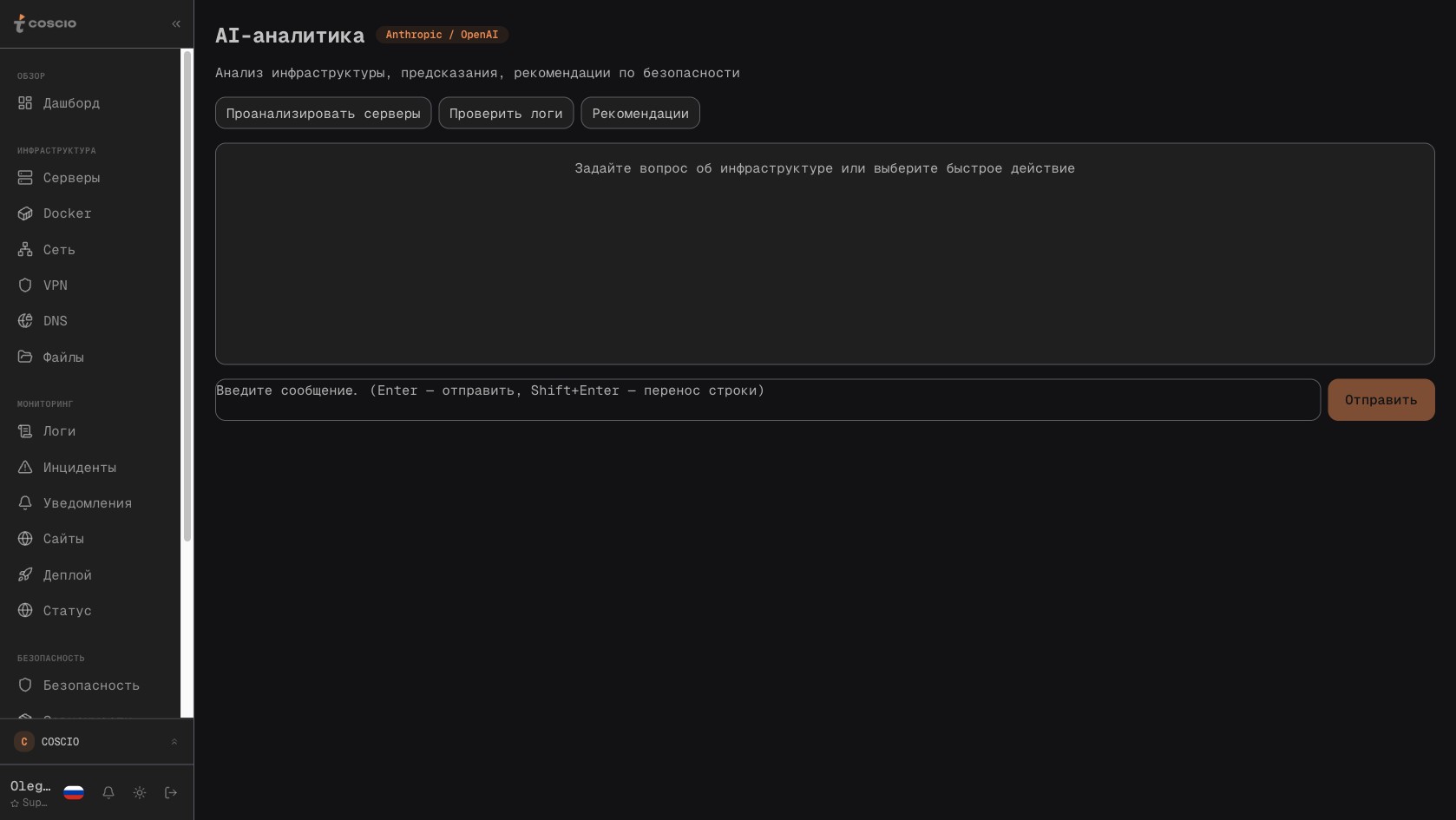
DevOpsMarch 14, 202625 min
AI как операционный слой инфраструктуры: разбор инцидентов через Claude и GPT, поиск закономерностей в логах, ранние сигналы сбоев
Read
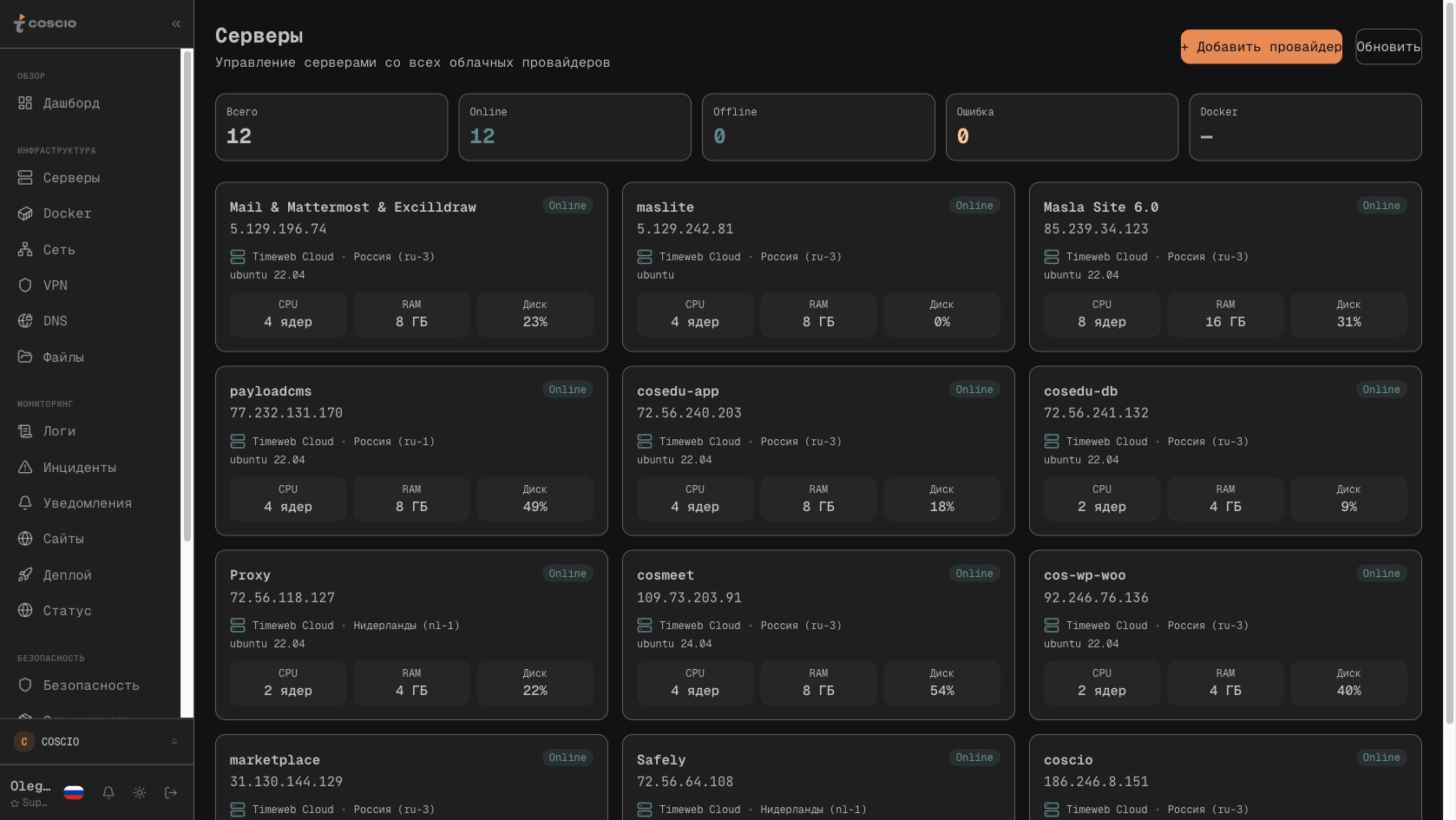
ИнтеграцииMarch 14, 202625 min
Сквозной мониторинг бизнес-систем: серверы, Bitrix24, 1С и WordPress в едином операционном дашборде IT-директора
Read
DevOpsMarch 14, 202625 min
Когда Prometheus и Grafana избыточны: интегрированный мониторинг Docker в едином портале инфраструктуры
Read
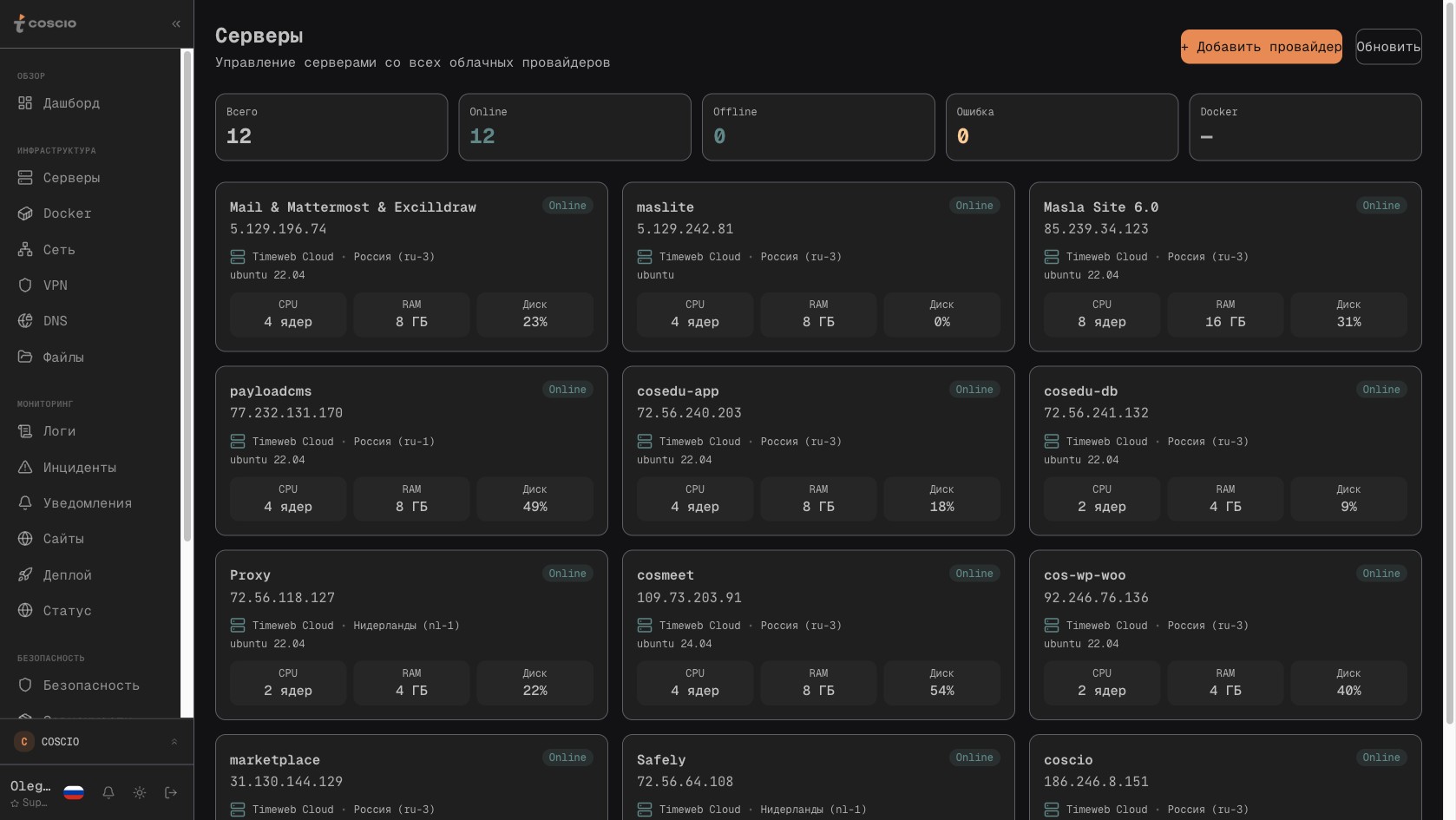
МониторингMarch 14, 202624 min
Парк серверов в 10-20 единиц в нескольких облаках: архитектура единого окна управления, метрики и операции из одного интерфейса
Read
МониторингMarch 14, 202624 min
Когда мониторинг превращается в обузу: семь признаков того, что стек устарел, и как современный портал инфраструктуры закрывает каждый из них
Read
ОбновленияMarch 14, 202624 min
Единый портал IT-директора: как централизованное управление инфраструктурой меняет работу технического департамента
Read
newsletter
Bi-weekly digest in your inbox
New posts and occasional feature announcements. No spam, one-click unsubscribe.