Если открыть любой DevOps-чат и спросить, как мониторить Docker, в первые пять минут прилетит готовый рецепт. Поднимаете Prometheus, рядом ставите Alertmanager, цепляете node-exporter на каждый хост, для контейнеров — cAdvisor, сверху накатываете Grafana с двумя десятками дашбордов из коробки. Возможно, добавите Loki для логов и Tempo для трейсов, чтобы получился полный observability-стек. Решение настолько стандартное, что обсуждать его как будто и не о чем — все так делают, значит, и вам надо. Вопрос только в том, насколько хорошо вы это настроите.
И вот тут начинается интересное. Потому что "все так делают" — это не аргумент. Это инерция. Прометеевский стек создавался не для команды из трёх инженеров, у которой десять виртуалок в Timeweb и пятьдесят контейнеров на всех. Он создавался для Google-масштабов, для SoundCloud, для компаний, у которых тысячи серверов, десятки тысяч контейнеров, сотни микросервисов и отдельные SRE-команды, для которых PromQL — это рабочий язык, как SQL для аналитика. Когда этот стек проникает в небольшие команды — а проникает он туда массово, потому что это "best practice" — он приносит с собой все свои предположения о масштабе. И эти предположения превращаются в постоянную нагрузку, которую никто не считает, но которую все платят.
Раздел Docker в COSCIO: все контейнеры со всех серверов в одной таблице, с состоянием, ресурсами и быстрыми действиями
Стоит остановиться и честно посчитать, во что обходится "стандартный" мониторинг Docker, если у команды нет выделенного SRE. Развёртывание базовой связки Prometheus плюс Grafana плюс Alertmanager занимает у опытного человека один-два дня, у неопытного — неделю с погружением в документацию. Настройка scrape configs для каждого нового сервера — ещё час-два на сервер, и это в случае, если ничего нестандартного. Написание правил алертинга в YAML — отдельная история, в которой легко получить либо тишину при реальных проблемах, либо шторм ложных срабатываний при каждом скачке нагрузки. Дашборды в Grafana — формально готовые, фактически их надо подогнать под себя, потому что дефолтные показывают всё подряд и ничего конкретно. Это всё разовые работы, и их можно перетерпеть.
Но дальше начинается операционка. TSDB Prometheus растёт. На сервере с пятидесятью контейнерами при интервале сбора в 15 секунд база раздувается на десятки гигабайт в месяц. Retention обычно ставят пятнадцать-тридцать дней, чтобы не утонуть, и тут же выясняется, что аналитика "что было три месяца назад" недоступна — только если поднимать Thanos или Cortex, а это уже отдельный проект с отдельной сложностью. node-exporter и cAdvisor едят свою долю CPU и памяти на каждом хосте — немного, но они есть всегда. Алерты надо тюнить, потому что то, что выглядело разумным порогом в момент настройки, через месяц оказывается либо слишком мягким, либо слишком жёстким. Когда обновляется Prometheus или Grafana — а они обновляются регулярно, — надо проверять, что breaking changes не сломали ваши правила и дашборды. Когда меняется инфраструктура — добавили сервер, переименовали контейнер, поменяли labels — приходится править конфиги в нескольких местах.
И ключевое — в команде должен быть человек, который понимает, что такое recording rules, чем отличается rate от irate, как работают histogram_quantile и subqueries. Без этого человека Grafana постепенно превращается в кладбище дашбордов, которые "когда-то кто-то настроил, но он уже уволился", алерты молчат или орут в чат, а на инциденты всё равно реагируют по факту падения сайта, а не по проактивному уведомлению. Это не теоретическая проблема — это типовой сценарий в десятках небольших и средних компаний, которые подсмотрели "правильный" стек у больших и попытались скопировать его без скопированной команды.
Теперь вопрос — а что на самом деле нужно небольшой команде от Docker-мониторинга? Если убрать из ответа всё, что навеяно best practices и оставить только то, что реально пригождается раз в неделю, список получится короткий. Видеть, какие контейнеры запущены и в каком они состоянии. Видеть, сколько они потребляют памяти и процессора, чтобы понимать, не пора ли увеличивать ресурсы или, наоборот, не утекает ли что-то. Получать уведомление, когда контейнер упал или начал перезапускаться по кругу. Иметь возможность быстро посмотреть логи и перезапустить контейнер, не лезя по SSH с командами вручную. Иметь общий вид по всем серверам, а не открывать пятнадцать терминалов параллельно. Это всё. На эти задачи Prometheus как платформа избыточен на пару порядков.
Платформа COSCIO построена ровно с этой философией. Docker-мониторинг в ней не отдельный продукт со своей инфраструктурой, а одна из вкладок единого портала, в котором живут серверы, контейнеры, репозитории, логи, инциденты, бэкапы, VPN, мониторинг сайтов, DNS, SSL-сертификаты и всё остальное, что должно быть у IT-директора под рукой. Архитектурно это Next.js 16 на App Router, PostgreSQL как единое хранилище и BullMQ-воркеры как механизм фоновых задач. Никакого Prometheus в стеке нет. Никакого Pushgateway. Никаких exporters на хостах. И никакого выделенного TSDB.
Карточка сервера с вкладкой Docker — контейнеры именно этого хоста, с действиями restart и просмотром логов прямо из интерфейса
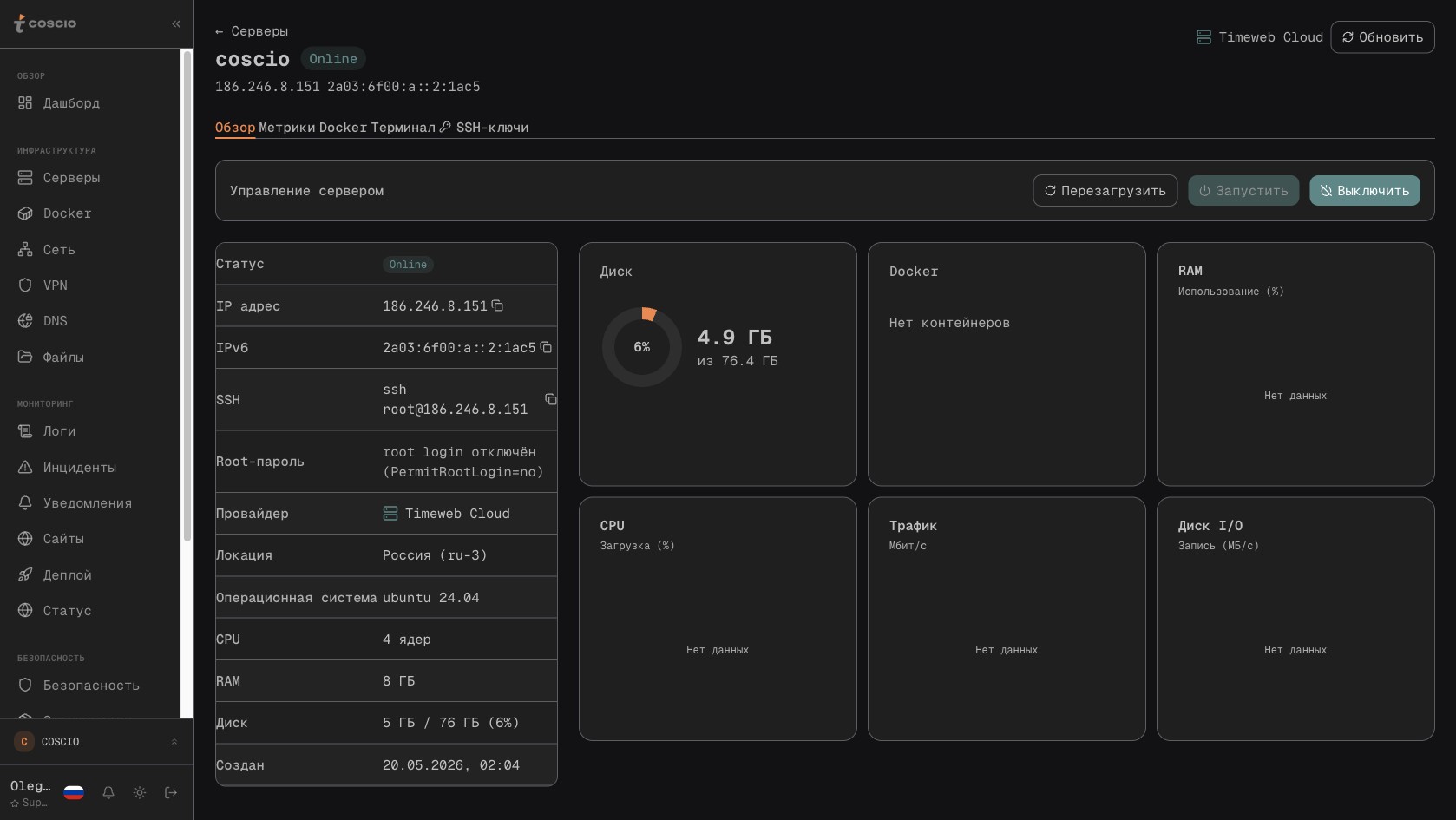
Как это работает технически. На каждом сервере, который подключен в платформу, не устанавливается ничего, кроме обычного OpenSSH, который и так есть. BullMQ-воркер в отдельном процессе раз в минуту обходит все серверы из docker queue, открывает SSH-сессию и выполняет две команды. Первая — sudo docker ps с форматированным выводом по нужным полям: имя, образ, статус, порты, время создания, labels. Вторая — docker stats с флагом --no-stream, чтобы получить мгновенный срез по CPU и памяти без постоянного стриминга. Обе команды отрабатывают за полторы-две секунды на хост, результат парсится воркером и сохраняется в Postgres через prisma upsert в таблицу Container. Ключ — комбинация идентификатора сервера и имени контейнера, поэтому повторные сборы просто обновляют существующие записи. Никаких очередей метрик, никакой ремоут-записи, никакого pull-моделирования — самый прямой путь от источника данных до базы.
Этого минимализма достаточно, чтобы покрыть все перечисленные выше задачи. На главной странице Docker отображается общий список контейнеров со всех серверов с фильтрами по статусу, по серверу, по образу. На каждой строке — текущее состояние, аптайм, потребление RAM и CPU, проброшенные порты, тег образа. На странице конкретного сервера — отдельная вкладка Docker с контейнерами только этого хоста и быстрыми действиями: рестарт, остановка, просмотр логов, инспекция. Действия выполняются не через какой-то промежуточный слой, а тем же SSH-каналом, тем же воркером — он принимает команду из контейнерного API, открывает сессию, выполняет docker restart или docker logs, возвращает результат. Логи отображаются прямо в интерфейсе, без необходимости заходить на сервер.
Цена этого решения по ресурсам — почти ноль. На сервере не крутятся посторонние процессы, экспортирующие метрики каждые пятнадцать секунд. Нет TSDB, которая ест диск. Нет отдельной Grafana, которой нужен свой инстанс и своя авторизация. SSH-нагрузка от платформы — это две команды в минуту на хост, в сумме секунды CPU в час. Postgres в основной базе платформы хранит таблицу контейнеров, которая для парка в двести контейнеров занимает мегабайты, а не десятки гигабайт. Историю можно агрегировать почасово или посуточно встроенными SQL-средствами и хранить хоть годами — стоить это будет копейки.
Дальше встаёт логичный вопрос — что теряется. И на этот вопрос важно отвечать честно, а не пытаться представить простое решение как "ничем не хуже Prometheus". Терять есть что, и нужно понимать, готовы ли вы это потерять.
Первое и главное — нет высокочастотных метрик с гранулярностью в секунды. Один сбор раз в минуту — это совсем не то же самое, что scrape каждые пятнадцать секунд. Если контейнер за тридцать секунд успел подняться, отъесть память до OOM-killer и упасть, в минутном срезе это, возможно, не будет видно вообще — воркер придёт после смерти и просто увидит, что контейнер не запущен. Для большинства реальных проблем — медленных утечек памяти, постепенного роста CPU, переходных рестартов — минутной гранулярности хватает с большим запасом. Но если бизнес требует видеть всплески нагрузки внутри секунды, потому что от этого зависит SLA на латентность ответа, то такой подход не подходит, и Prometheus — правильный выбор. Хотя для Docker-мониторинга такие требования встречаются у единиц компаний из всех, кто его внедряет.
Второе — нет языка запросов уровня PromQL. Если задача "посчитать перцентиль 95 потребления памяти по контейнерам с лейблом environment=production за последние семь дней с группировкой по типу сервиса", её в SQL придётся писать руками или вытаскивать данные и считать снаружи. PromQL для подобных задач удобнее. Но снова вопрос — насколько часто это реально делается? В большинстве команд аналитика метрик ограничивается "покажи график CPU за последние сутки" и "сколько раз контейнер падал на этой неделе". Эти запросы прекрасно решаются обычным SQL, и не требуют осваивать отдельный DSL.
Третье — нет federation между датацентрами в академическом смысле. Если у вас три региона по сто серверов и нужно собирать локальные Prometheus, потом федерировать в центральный, фильтровать там, агрегировать и хранить — да, это задача для Prometheus. Но в COSCIO единый дашборд достигается иначе: BullMQ-воркеры могут собирать данные с серверов в разных регионах через SSH одинаково, всё попадает в одну Postgres-инстанс, и общий вид получается автоматически. Это работает до тех пор, пока количество серверов умещается в пропускную способность одной базы — а для нескольких сотен это так. Дальше — да, придётся думать про распределение, но это не общий случай.
Четвёртое — нет готовой экосистемы тысяч дашбордов и алертов с GitHub. Сообщество вокруг Prometheus огромное, скачать готовый дашборд для PostgreSQL или Redis — дело пары минут. В COSCIO дашборды встроенные, и если вам нужно что-то очень специфическое, чего нет в стандартном наборе, придётся либо ждать обновления, либо мириться с тем, что есть. Для типового набора задач этого достаточно, для редких — нет.
Настройки платформы: пороги для Docker-мониторинга — память, процессор, количество перезапусков. Меняются прямо в админке, без правки YAML
Теперь о том, что приобретается, и это, пожалуй, важнее, чем то, что теряется. Прежде всего — кардинальное снижение операционной нагрузки. На серверах не нужно ничего ставить дополнительно. Это значит, что и обновлять там нечего, и ломать обновлением нечего. node-exporter не упадёт в неподходящий момент. cAdvisor не съест неожиданно лишний гигабайт памяти. Когда добавляется новый сервер, его не нужно прописывать в scrape config — он просто появляется в списке серверов платформы, и со следующей итерации воркера данные о его контейнерах начинают поступать в общий дашборд. Auto-discovery в самом прямом смысле: если на сервере есть Docker, на странице сервера автоматически появляется вкладка Docker.
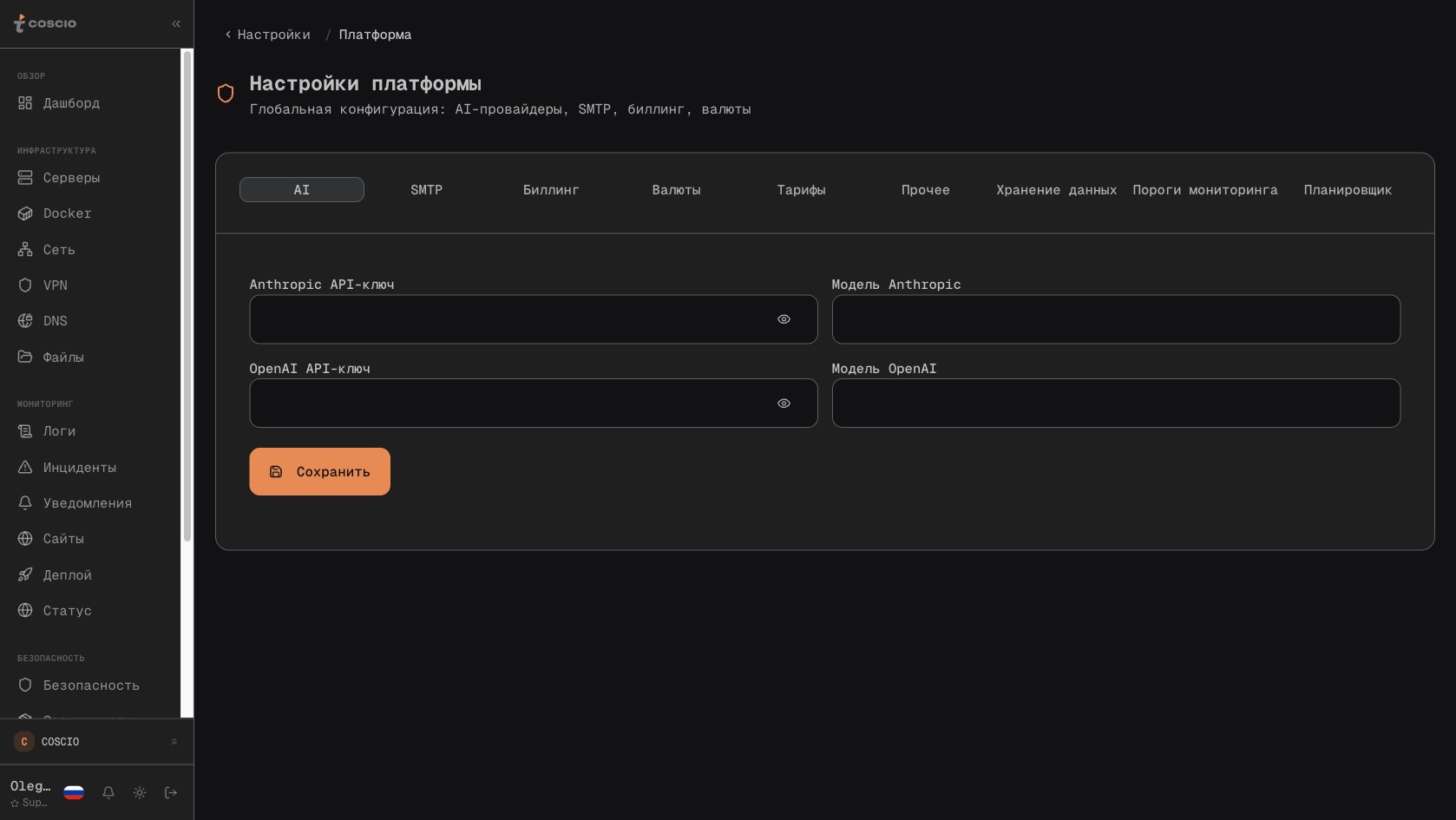
Следующий бонус — отсутствие отдельной системы алертов. Нет Alertmanager с его правилами в YAML, нет необходимости держать в голове особенности группировки, инхибирования и routing-tree. Пороги для Docker-метрик настраиваются прямо в интерфейсе платформы, на странице Settings → Platform → Thresholds. Восемь параметров: пороги по RAM, по CPU, по количеству рестартов за определённое окно, по продолжительности находения в статусе restarting, и ещё несколько. Меняется значение в форме — следующая итерация воркера применяет новый порог при анализе. Превышение порога создаёт инцидент во встроенной системе инцидент-менеджмента. Инцидент через notification dispatcher разлетается по настроенным каналам — Email, Telegram, SMS, Mattermost — в зависимости от настроек уведомлений конкретного пользователя или команды. Никакого отдельного UI Alertmanager, никаких silence через CLI, никаких манипуляций с матчерами. Всё в одном месте, для всех типов мониторинга — серверов, сайтов, контейнеров, дисков, SSL-сертификатов.
Третий бонус, который обычно недооценивают — единый контекст. Когда контейнер падает, и приходит уведомление в Telegram, по ссылке открывается страница того самого контейнера в COSCIO. На этой странице видно не только текущий статус, но и историю состояний за последние часы, последние записи логов, сервер, на котором он крутится, образ, переменные окружения. С этой же страницы можно перезапустить контейнер. Если нужно понять, нет ли проблемы шире — открываются логи сервера, и видно, что в системе происходило в момент падения. Если падало несколько раз — открывается история инцидентов по этому контейнеру и видно, был ли паттерн. В классическом стеке этот контекст разнесён между Grafana, Alertmanager UI, отдельным просмотрщиком логов, отдельной системой инцидентов в Jira или PagerDuty, и SSH-сессией к серверу. Каждый переход — это копирование идентификаторов, переключение вкладок, потеря времени.
Раздел логов: события со всех серверов в одной ленте, с фильтрацией по источнику — серверы, Docker, CRM-интеграции, приложение
Четвёртый бонус, и тут уже архитектурное преимущество — данные в Postgres, а не в TSDB, и поверх них можно строить аналитику, которую с time-series базой сделать почти невозможно. В COSCIO на той же базе работают модули cost-manager (анализ затрат по серверам с привязкой к их утилизации), ai-incident-analysis (Claude и GPT берут историю инцидентов, метрик и логов и формируют рекомендации), prediction (прогноз исчерпания ресурсов на основе исторических трендов). Эти модули делают сложные джойны между таблицами серверов, контейнеров, инцидентов, расходов, пользовательских действий. С Prometheus это пришлось бы делать через ETL — выгружать метрики, преобразовывать, загружать в нормальную базу, потом анализировать. В унифицированной модели это просто запрос с несколькими JOIN. Это качественно другой уровень возможностей для бизнес-аналитики, которая обычно у небольших команд просто не делается, потому что технически дорого её настраивать.
Пятый — нулевой риск утечек метрик. Метрики Prometheus по умолчанию открыты на /metrics эндпоинте, и если экспортер случайно повесили на публичный интерфейс или забыли закрыть порт фаерволом, наружу торчит детальная информация о вашей инфраструктуре. История знает случаи, когда такие открытые эндпоинты приводили к утечкам конфиденциальной информации — имена внутренних сервисов, версии ПО, паттерны нагрузки. В подходе с SSH-сборкой метрики никогда не выходят за пределы серверов в открытом виде — они снимаются изнутри и сохраняются в защищённой базе платформы.
Шестой, и менее очевидный, бонус — единая модель прав доступа. В классическом стеке прав три набора: на серверы (SSH-ключи), на Prometheus и Grafana (свои пользователи, обычно интегрированные с LDAP или OAuth), на Alertmanager (иногда отдельно). Когда нанимается новый человек, ему надо настроить доступы в трёх местах. Когда он увольняется — отозвать в трёх местах. И обычно где-то забывают. В унифицированной модели COSCIO человек либо есть в workspace и видит всё, что ему положено по роли, либо нет — и не видит ничего. Тот же логин даёт доступ к серверам, к Docker, к логам, к инцидентам. Это упрощает не только эксплуатацию, но и аудит безопасности — кто что когда видел и делал, всё в одном журнале действий, а не в трёх разных системах с разными форматами.
Седьмой бонус для распределённых команд — мобильность. Дашборд платформы — это веб-интерфейс, который одинаково работает с ноутбука, с планшета и с телефона. Когда в пятницу вечером прилетает алерт о падении контейнера, ответственный человек открывает приложение в телефоне, видит ситуацию, запускает рестарт прямо с мобильного. Делать то же самое с Grafana формально можно, но обычно дашборды не адаптированы под маленький экран, и для действий всё равно нужен SSH-клиент. В унифицированной платформе действия — это просто кнопки в интерфейсе, которые работают с любого устройства, лишь бы был интернет и нормальная аутентификация по TOTP.
Стоит отдельно сказать про обновления и эволюцию. Prometheus-стек состоит из множества независимых компонентов, у каждого свой релизный цикл, свои breaking changes, свои миграционные процедуры. Обновление с Prometheus 2.45 на 2.50 — это обычно проверка совместимости с используемыми exporters, проверка работы recording rules, иногда правка scrape configs. Обновление Grafana с одной мажорной версии на другую — это чтение release notes, проверка дашбордов на совместимость с новой версией визуализаций, иногда переписывание панелей. Обновление Alertmanager — отдельная история с проверкой routing rules. И всё это надо делать на тестовом стенде, потому что выкатывать сразу в прод рискованно. Когда мониторинг — это часть монолитной платформы, обновление — это один процесс деплоя самой платформы. Релиз протестирован разработчиками, миграции описаны, изменения в дашбордах учтены автоматически. Команда эксплуатации просто запускает деплой и не тратит дни на синхронизацию версий разных компонентов.
Восьмой аспект, о котором редко думают на этапе выбора стека, — стоимость подключения нового члена команды к работе с мониторингом. С Prometheus новому человеку придётся освоить минимум четыре концепции: модель метрик и labels, язык запросов PromQL, синтаксис правил алертинга, базовые операции Grafana по построению дашбордов. На это уходят недели, и без практики навыки быстро забываются. В унифицированной платформе новичок открывает интерфейс, видит привычные веб-страницы со списками и графиками, разбирается за час-два. Это значит, что мониторинг перестаёт быть зоной ответственности одного-двух экспертов, и его может смотреть и эксплуатировать любой инженер в команде. Это качественно меняет отношение к мониторингу — он становится повседневным инструментом, а не специализированной системой, к которой обращаются только когда что-то сломалось.
Теперь немного про практику и сценарии, где этот подход показывает себя именно с лучшей стороны. Один из типовых случаев в любой команде, эксплуатирующей Docker, — контейнер начинает периодически перезапускаться. Не падает совсем, не уходит в restarting permanently, но раз в полчаса-час уходит на рестарт, потом поднимается, и так по кругу. Если мониторинга нет вообще, такие циклы могут жить неделями, проявляясь только в виде странных тайм-аутов у пользователей. Если мониторинг есть, но это голый Prometheus с алертом "контейнер не работает 5 минут" — алерт не срабатывает, потому что контейнер каждый раз быстро поднимается, и интегральная availability остаётся высокой. В COSCIO порог по количеству рестартов за окно — отдельный параметр, и если за час контейнер перезапустился три раза, создаётся инцидент. Открывается страница контейнера, видна история состояний — действительно, циклы каждые 25-30 минут. Открывается вкладка логов прямо там же — видно, что в логах OutOfMemoryError или unhandled exception при обработке очередного типа сообщений. Решение — увеличить лимит памяти или починить обработчик, и это делается за десять минут от уведомления до фикса. Без переключения между пятью инструментами.
Другой сценарий — нужно понять, какие контейнеры суммарно сколько ресурсов едят на конкретном сервере, потому что сервер начал упираться в потолок. Можно зайти на сервер по SSH и запустить там docker stats вручную — но это срез на одну секунду, и понять, кто хронически нагружает, по нему сложно. В Prometheus с готовым дашбордом — да, видно, но придётся помнить, какой дашборд это показывает, и фильтровать по нужному хосту. В COSCIO — открывается страница сервера, на вкладке Docker контейнеры этого хоста с текущим потреблением, отсортированные по нужному столбцу. Видно, что условный cosbi-app занимает 4 ГБ из 8 на сервере, рядом ещё один контейнер с базой ест 2 ГБ, и понятно, куда ушли ресурсы.
Третий сценарий, особенно полезный для технических руководителей — общая картина по парку. Сколько всего контейнеров крутится в инфраструктуре. Сколько из них в running, сколько в stopped, сколько в restarting прямо сейчас. На каких серверах сосредоточены критичные сервисы. Какие образы и каких версий используются — нет ли где-то старого образа с известной уязвимостью. Этот аналитический срез в Prometheus делается через PromQL, который надо уметь писать. В COSCIO это просто страница Docker с готовыми фильтрами и счётчиками. Зашёл, посмотрел, ушёл — пятнадцать секунд.
Главный дашборд платформы: контейнеры в общей сводке вместе с серверами, инцидентами, логами и аналитикой
Стоит явно обозначить границы применимости. Подход с SSH-сборкой и хранением в Postgres хорошо работает для парков примерно до двухсот контейнеров на десяти-двадцати серверах. За этой границей начинают вылезать ограничения — нагрузка на основную базу растёт, минутная гранулярность может становиться недостаточной, аналитика по всему парку требует более продуманных индексов и партиционирования. Если у вас две тысячи контейнеров на ста серверах в трёх ЦОДах — это уже не средняя команда, это полноценная платформенная история, и там Prometheus оправдан, но и Kubernetes, и сервис-меш, и выделенный SRE-отдел тоже оправданы. Граница не точная, у каждой команды она своя в зависимости от характера нагрузки, но как ориентир — до двухсот контейнеров реально хватает и сильно проще, дальше начинаются нюансы, после пятисот точно нужен другой подход.
Также не подходит этот подход, если требования к мониторингу включают высокочастотные SLO-метрики уровня "латентность ответа в перцентиле 99 за окно в минуту". Это уже задача не Docker-мониторинга, это задача APM, и тут место для Datadog, New Relic или OpenTelemetry с собственным backend. Docker-мониторинг в смысле "состояние контейнеров и потребление ресурсов хостом" — это другая задача, и она вполне решается простыми средствами.
И ещё одно важное наблюдение, к которому имеет смысл прийти явным образом. Indostry-стандарт — это часто индустрия-стандарт, а не разумность-стандарт. Многие технологические выборы в команды попадают по принципу карго-культа: "крупные компании используют X, значит, мы тоже должны". Но крупные компании используют X в своих условиях, со своими ресурсами, с командой, которая знает X на уровне коммитеров в код. Когда X переносится в условия, для которых он не создавался, происходит то, что обычно и происходит — стек работает, но требует постоянного внимания, никто кроме одного человека в команде его толком не понимает, и весь проект становится заложником этого человека. Когда он уходит, начинается известная история про "почему у нас сломался мониторинг и никто не может починить".
Альтернативный подход — выбирать инструменты под свой реальный масштаб, а не под предполагаемый будущий или подсмотренный у других. Если у вас десять серверов, не нужно строить инфраструктуру для тысячи. Если позже понадобится — переход не такой драматичный, как кажется. SQL-запросы к Postgres легко переписать в PromQL, дашборды в Grafana построить заново, экспортеры развернуть. То, что вы построили простое, не закрывает путь к сложному в будущем — оно просто откладывает сложность до того момента, когда она действительно понадобится. А вот обратно — со сложного на простое — почти никогда не идут, потому что психологически сложно "снижать стандарты", даже когда они избыточны.
С точки зрения архитектуры COSCIO интересно ещё то, как Docker-мониторинг встроен в общую модель платформы. Нет специальной таблицы "метрики", есть таблица Container, у которой поля статуса, ресурсов, времени последнего обновления. Это нормальная реляционная модель, и она прекрасно интегрируется с остальной схемой: связи с Server, через Server с Organization (рабочим пространством в терминах UI), с Incident, который ссылается на конкретный контейнер. Когда в системе возникает уведомление "контейнер cosbi-app превысил порог памяти", оно создаётся как Incident с типом docker-health и привязкой к containerId. Когда пользователь открывает инцидент, видит контекст: какой контейнер, какой сервер, какая команда отвечает за этот сервис (потому что в Organization есть структура owners). Когда инцидент закрывается, время разрешения попадает в метрики команды — сколько времени в среднем у них уходит на реакцию. Это уже не мониторинг в смысле "график на стене", это интегрированный operations-cycle, в котором мониторинг — одна из шестерёнок, а не отдельная система.
С точки зрения разработчика, который добавляет новые типы метрик или новые типы алертов в COSCIO — тоже всё проще. Добавить новый тип проверки Docker — это добавить функцию в worker, прописать в queue, добавить порог в settings, добавить отображение в UI. Никакой работы с TSDB, никакой адаптации Prometheus exporter, никакой настройки rule files. Цикл фича-в-проде сокращается в разы, что для развивающейся платформы критично.
Резюмируя, без банальностей и без морализаторства. Prometheus и Grafana — отличные инструменты для задач, под которые они созданы. Это задачи большого масштаба, высокой гранулярности, сложной аналитики и работы с метриками как с самостоятельным доменом. Если у команды этот масштаб есть и эти задачи стоят — выбор очевиден. Если масштаба нет, но кажется, что иначе несерьёзно — это иллюзия. Несерьёзно — это таскать за собой инфраструктуру, которую не используешь, тратить на её сопровождение часы каждую неделю, и держать в команде заложника-эксперта по PromQL, без которого ничего не работает. Серьёзно — это решать задачу адекватными её масштабу средствами и не платить лишнего ни деньгами, ни временем, ни сложностью.
Подход, реализованный в COSCIO для Docker-мониторинга, — это пример такого адекватного решения. Минута интервала, две SSH-команды, обычная таблица в Postgres, встроенный UI с действиями, пороги через интерфейс, инциденты и уведомления в общей системе. Никакой магии, никакой избыточности, никаких лишних компонентов. И именно эта простота даёт неожиданное качество — система работает годами без специального обслуживания, новые серверы подключаются автоматически, аналитика возможна на уровне обычного SQL, интеграция с другими модулями платформы естественная, потому что данные живут в одной реляционной модели.
Когда инструмент проще, чем требует задача, его нужно усложнить. Когда инструмент сложнее, чем требует задача, его нужно либо упростить, либо заменить. Большинство команд оказываются во втором случае с Prometheus-стеком и почему-то не решаются на замену, считая это шагом назад. Хотя на самом деле это шаг вперёд — от инфраструктуры, обслуживающей саму себя, к инфраструктуре, обслуживающей бизнес. И этот шаг открывает время и силы для того, что действительно важно — для построения сервисов, которые приносят пользу пользователям, а не для бесконечного тюнинга мониторинга, который мониторит сам себя.
Если посмотреть шире, то описанная история про Docker-мониторинг — это частный случай более общего паттерна, который проявляется в любой инженерной команде. Сначала выбирается "правильный" с точки зрения индустрии инструмент. Потом тратятся месяцы на его освоение и настройку. Потом начинается операционка по его сопровождению. Потом инструмент становится частью архитектуры, без которой ничего не работает. Потом, через год или два, кто-то наконец задаёт вопрос — а зачем нам это всё? И выясняется, что 80% функциональности этого инструмента не используется никогда, 15% используется раз в полгода, а оставшиеся 5% — это то, ради чего его всё это время и держали. Этих 5% обычно достаточно для собственного простого решения, которое весит в десять раз меньше и не требует выделенного эксперта.
Такие моменты пересмотра инструментария крайне полезны. Не для того, чтобы радикально всё выкинуть — это другая крайность, в которой команды лишают себя нужного. А для того, чтобы честно посмотреть, что используется, что не используется, что приносит ценность, что приносит только нагрузку. По итогам этого взгляда обычно оказывается, что инфраструктуру можно упростить минимум на треть, а то и наполовину, без потери реальной функциональности. Это освобождает ресурсы — и человеческие, и серверные, и денежные — для того, что действительно двигает бизнес вперёд.
В случае с мониторингом Docker этот пересмотр приводит к одному из двух выводов. Либо да, наш масштаб и наши задачи действительно требуют Prometheus с federation, Thanos для долгосрочного хранения, и полноценной SRE-команды, которая всё это поддерживает. Либо нет, нам достаточно знать, какие контейнеры работают, видеть их потребление, получать алерты при проблемах и иметь возможность быстро перезапустить. Второй случай встречается на порядки чаще, но решение по первому пути выбирается тоже на порядки чаще — просто потому, что "так принято". Принято — не значит правильно. Правильно — это адекватно своим реальным потребностям, без оглядки на чужие best practices, выработанные для совсем других условий.
COSCIO как платформа целиком построена на этом принципе. Каждый модуль решает свою задачу самыми простыми средствами, которые её решают. SSH вместо агентов везде, где это возможно. Postgres вместо специализированных хранилищ везде, где данных не настолько много, чтобы Postgres перестал справляться. BullMQ вместо сложных оркестраторов задач, потому что для большинства фоновых работ его более чем достаточно. И именно этот минимализм даёт платформе её главное качество — она работает, не требуя постоянного внимания, и оставляет команде время на содержательные задачи. Мониторинг Docker — лишь один из примеров этого подхода, и, наверное, один из самых наглядных. Потому что именно вокруг Docker-мониторинга сложился самый укоренённый карго-культ, и именно его развенчание особенно убедительно показывает, что в инженерии простота — это не отсутствие зрелости, а её высшая форма.
Любопытно наблюдать, как меняется отношение команд после перехода на простую модель. Первая реакция — недоверие. Кажется, что без Prometheus и Grafana мониторинг будет неполноценным, что вот-вот случится что-то важное, что без классических инструментов не отследить. Проходит месяц — и оказывается, что все нужные сигналы прилетают, все нужные действия делаются, все нужные графики видны. Проходит три месяца — и инженеры начинают замечать, сколько времени они раньше тратили на администрирование самого мониторинга вместо того, чтобы заниматься продуктом. Проходит полгода — и вопрос "может, нам всё-таки поставить Prometheus" даже не возникает, потому что задачи, ради которых его раньше держали, оказываются решены другим способом, дешевле и удобнее. Это не магия и не маркетинг — это просто результат того, что инструмент подобран под реальный масштаб, а не под воображаемый.
И именно в этом, пожалуй, главный практический вывод. Перед тем как развернуть очередной "стандартный" стек, имеет смысл потратить пару часов на честный аудит — а нужен ли он вам в полном объёме, какие конкретно задачи он закроет, какие из этих задач можно закрыть проще, и во что обойдётся каждая дополнительная сложность в перспективе. Часто оказывается, что простой путь существует и он лучше во всех отношениях, кроме одного — он непривычен и за него не похвалят на профильных конференциях. Но за то, что инфраструктура работает годами без капризов, а команда занимается продуктом, а не сопровождением мониторинга, рано или поздно похвалят те, кому это действительно важно — пользователи и собственный бизнес.