Главная страница coscio.ru: концепция единого контроля IT-инфраструктуры
Если посмотреть, как устроена работа технического департамента в средней российской компании, картина почти везде одинаковая. Где-то стоит Grafana с десятком дашбордов, к которым прикручен Prometheus и пара экспортеров. Рядом крутится Zabbix, потому что Grafana настроили позже и переносить ничего не стали. У части серверов есть кабинет Timeweb, у другой части — Hetzner или AWS, у третьей — просто SSH-доступ к железу в офисе. Документация лежит в Notion, инциденты заводят в Jira или в чат, бэкапы складываются в S3, но интерфейса к ним нет, и приходится лезть в консоль. VPN поднят через wg-easy, сертификаты обновляются certbot из крона, домены ведутся в трёх разных регистраторах, DNS-зоны — в Cloudflare для одних проектов и у регистратора для других. К этому добавляются Bitrix24 для CRM, 1С для учёта, AmoCRM в одном из отделов и WordPress для маркетингового сайта. Каждая из этих систем живёт своей жизнью, и у каждой собственный интерфейс, права доступа, логин-пароль, окно для тревог.
В такой конфигурации главная проблема — даже не количество систем, а то, что между ними нет связности. Когда падает корпоративный сайт, инженер сначала смотрит в Uptime Kuma, потом идёт в Grafana, потом проверяет логи на сервере через ssh, потом смотрит, не уперлась ли база в диск, потом проверяет, не сменился ли IP у балансировщика. Если выясняется, что виноват провайдер, надо открыть кабинет провайдера, проверить статус заказа, написать в поддержку. Если виноват код — заглянуть в репозиторий, посмотреть последний деплой, сравнить с метрикой ошибок. Если виноват срок действия сертификата — открыть certbot на нужном сервере, продлить вручную, перезагрузить nginx. Каждая операция — отдельный инструмент, отдельный контекст, отдельный логин. Знание о том, где что лежит, концентрируется в голове одного-двух старших инженеров, и при их уходе бизнес остаётся с разрозненной коллекцией систем, в которой никто толком не разбирается.
Идея единого портала IT-директора родилась как ответ именно на эту проблему. Не как замена Grafana или Zabbix — узкоспециализированные инструменты сложно перебить в их собственной нише. А как слой над ними, объединяющий операционную работу: видеть состояние всей инфраструктуры в одном окне, выполнять действия из одного интерфейса, иметь сквозной аудит, кто и что сделал, держать единую точку входа для всех инженеров и для самого IT-директора, которому нужно понимать общую картину, а не нырять в каждую систему по отдельности. Платформа COSCIO построена ровно вокруг этой идеи. Внутри неё объединено около тридцати одного модуля, каждый закрывает свой класс задач, но все они живут в одном интерфейсе, под единой авторизацией, с общим поиском, общими уведомлениями и общими настройками доступа.
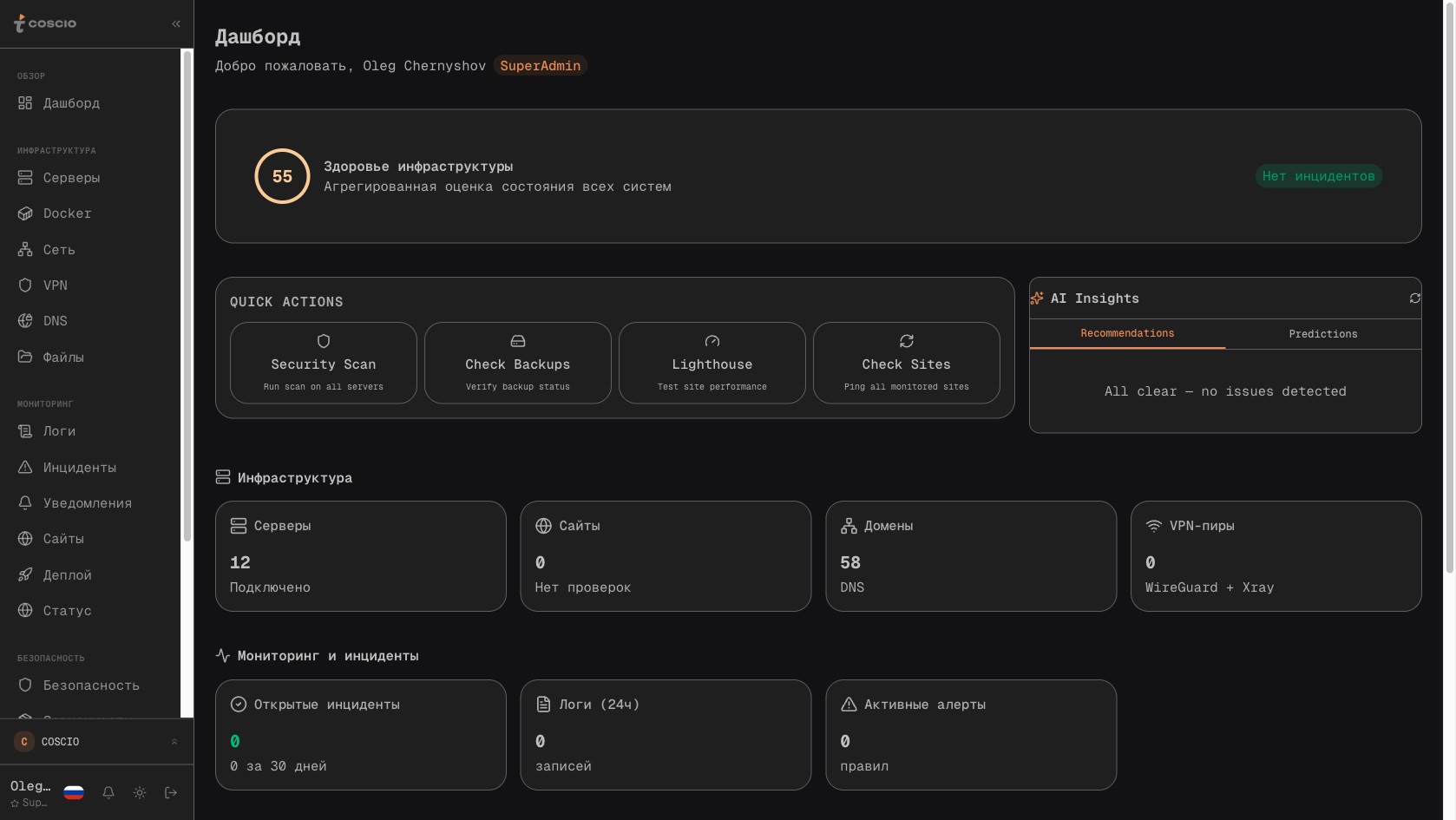
Главный дашборд после авторизации: AI-инсайты, сводка по серверам, состояние систем
Если открыть платформу впервые, первое, что бросается в глаза — длинная левая панель с разделами. Сверху идут разделы инфраструктуры: серверы, Docker, репозитории, сеть, DNS, файловый менеджер, бэкапы. Ниже — мониторинг и операции: логи, инциденты, статус систем, сайт-мониторинг, performance, traces, уведомления. Дальше — безопасность: сканирование зависимостей на CVE, threat intelligence, brute-force collector, remediation. Затем — бизнес-системы: Bitrix24, 1С, AmoCRM, WordPress, PayloadCMS. И наконец — инструменты разработчика: API-тестер, AI-аналитика, затраты по всем облакам, почта. В самом низу — настройки: профиль, рабочее пространство, интеграции, SSH-ключи, окна обслуживания, платформа целиком (для администратора). Эта структура отражает реальные слои работы технического департамента: сначала — что у нас есть, потом — как оно себя ведёт, потом — что делать, если что-то пошло не так, потом — как это связано с бизнесом, и только в конце — настройки самой платформы.
Серверный раздел — обычно первое, что открывает новый пользователь. И здесь сразу видно ключевую особенность платформы: серверы из разных облаков перечислены в одном списке. Можно подключить аккаунт Timeweb Cloud, аккаунт Hetzner, аккаунт AWS, аккаунт DigitalOcean, а можно добавить просто IP-адрес и SSH-ключ для своего собственного железа. Платформа абстрагирует разницу: для каждого сервера в списке есть статус, метрики CPU, RAM, диска, трафика, версия операционной системы, тариф, расположение, IP, провайдер. Если сервер поддерживает API провайдера — для него доступны операции рестарта, выключения, включения. Если это просто SSH-сервер — операции выполняются командами по SSH. Внутри это устроено через единую абстракцию CloudProvider с одинаковым набором методов listServers, getServer, getMetrics, reboot, start, shutdown, executeSSH. Каждый провайдер реализует этот интерфейс по-своему, но для пользователя разницы нет — он видит одну таблицу и одинаковые действия для всех серверов.
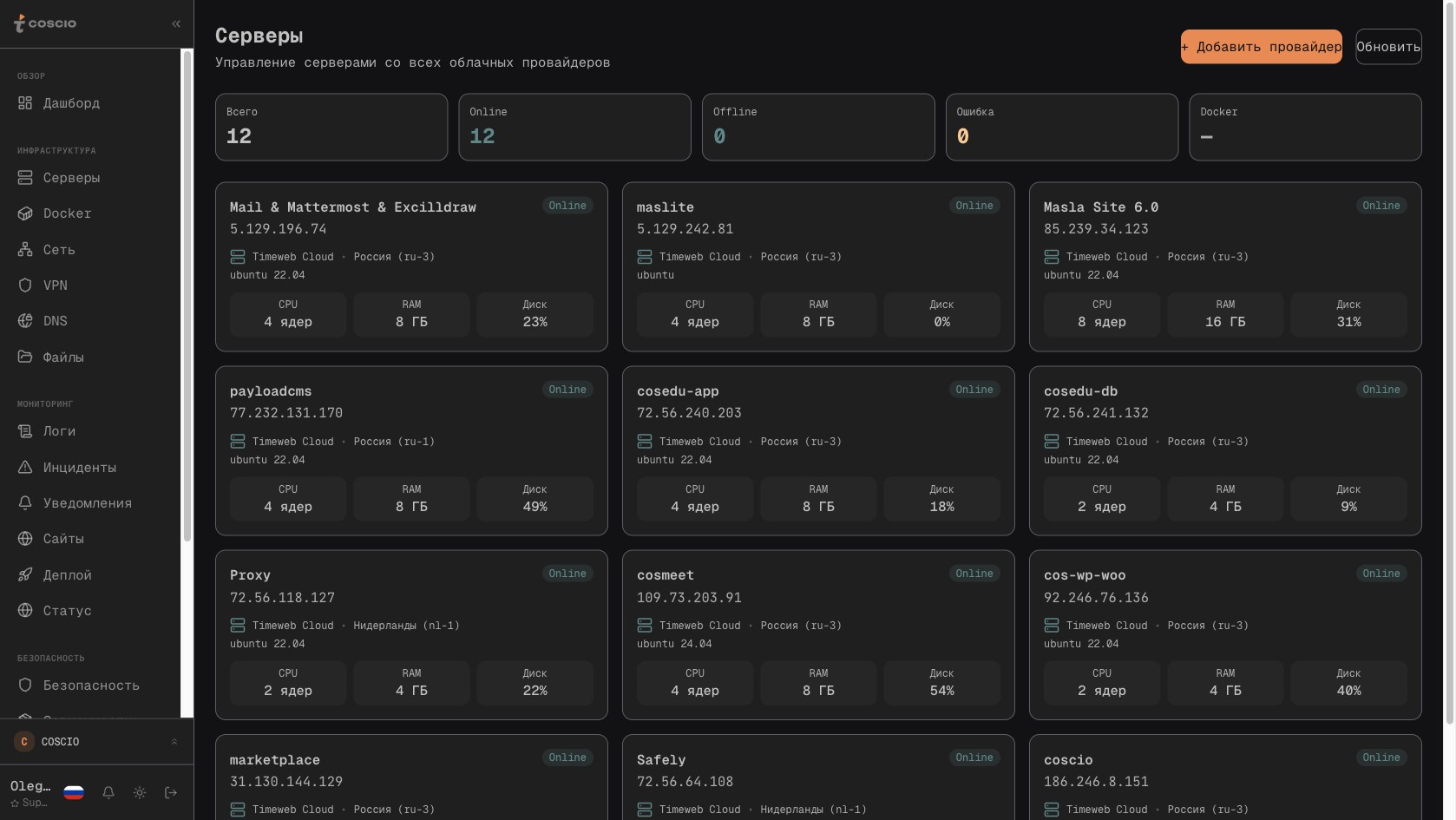
Список из двенадцати серверов, подключённых через один аккаунт Timeweb: статусы, метрики, действия
Когда инженер открывает конкретный сервер, он попадает в карточку с подробностями. Здесь и базовая информация: IP, готовая SSH-строка для копирования в терминал, провайдер, дата создания, тариф. Здесь и виджеты с метриками: диск с разбивкой по разделам, нагрузка на процессор за последние сутки, использование оперативной памяти, входящий и исходящий трафик. Здесь же вкладки с логами этого сервера, с docker-контейнерами на нём, с открытыми портами и сетевыми правилами, со встроенным веб-терминалом. Раньше во многих компаниях существовала отдельная страница «терминал» в дашборде — общий веб-терминал, в котором можно было выбрать сервер и подключиться. В COSCIO от этого подхода отказались, и терминал теперь живёт прямо внутри карточки конкретного сервера, как одна из вкладок. Это логичнее: операция почти всегда привязана к конкретной машине, и контекст не должен теряться между «общим терминалом» и страницей сервера.
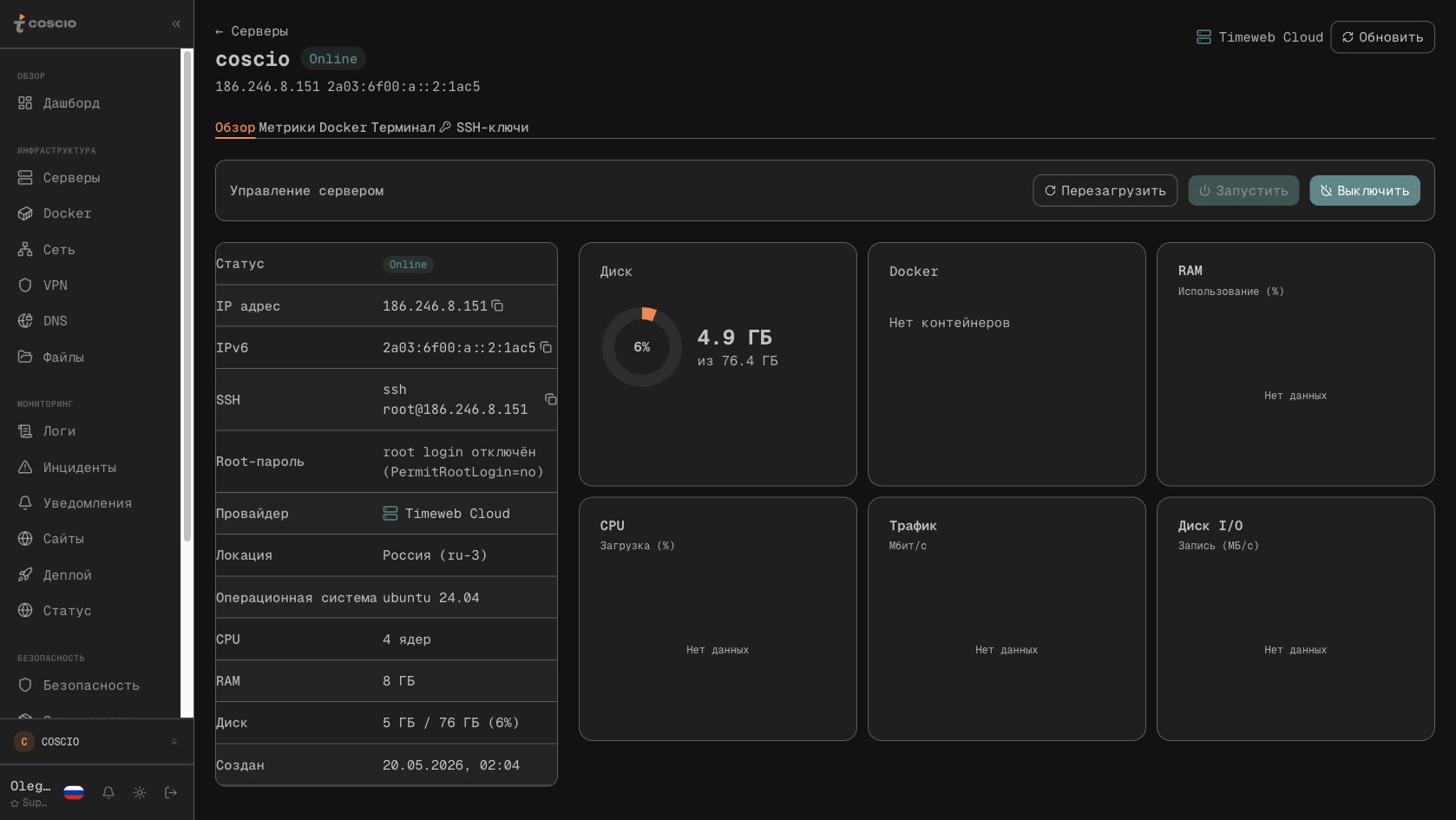
Карточка сервера: IP, SSH-строка, виджеты диска, CPU, RAM, трафика и список Docker-контейнеров
Docker-раздел работает поверх серверного. Платформа знает, какие из подключённых серверов имеют установленный Docker, обходит их по расписанию, собирает список контейнеров, их статусы, использование ресурсов, наличие healthcheck. Если контейнер падает или его healthcheck начинает отдавать ошибки — заводится инцидент. Если контейнер давно не обновлялся или сидит на устаревшем образе — это видно в общем списке и попадает в раздел зависимостей с CVE-сканированием. На дашборде есть отдельный виджет, показывающий общую долю «здоровых» контейнеров по всему парку — для IT-директора это одна из верхнеуровневых метрик, по которой можно быстро понять, есть ли где-то проблема.
Сетевой раздел собирает в одном месте всё, что связано с сетевой инфраструктурой. Локальные сети между серверами одного провайдера — например, приватные сети Timeweb, через которые можно соединить серверы без публичного трафика. Внешние домены: какой домен ведёт куда, какой A-запись, на каком регистраторе, когда истекает срок регистрации. SSL-сертификаты: где, для какого домена, когда истекает, как продлевается, какой удостоверяющий центр. DNS-зоны: список записей, провайдер DNS, история изменений. Когда у компании пятнадцать доменов и тридцать поддоменов, держать это в голове или в табличке невозможно — нужен единый реестр, в который сертификат сам прописывается при выдаче и сам пишет в инциденты, когда осталось меньше двух недель до истечения.
VPN — отдельный раздел, в котором поддерживается WireGuard и Xray. Не как два независимых решения, а как единый список клиентов, которым можно выдать конфиг любого из двух протоколов в зависимости от задачи. WireGuard используется для классической корпоративной сети, чтобы дать сотрудникам доступ к внутренним сервисам. Xray применяется там, где нужна устойчивая к блокировкам связь — например, для удалённых сотрудников в регионах с нестабильным интернетом. Из интерфейса можно сгенерировать новый ключ, отдать клиенту, отозвать, ограничить срок действия, посмотреть последнюю активность. Без этого администратору пришлось бы держать отдельную инсталляцию wg-easy для одного протокола и руками править конфиги Xray для второго, разнесённые по разным серверам.
Файловый менеджер — то, чего обычно не хватает в подобных продуктах. Это полноценный веб-клиент SFTP, который понимает структуру каталогов на сервере, умеет загружать и скачивать файлы, открывает текстовые файлы во встроенном редакторе CodeMirror с подсветкой синтаксиса и diff-режимом, позволяет менять права доступа и владельца. Для инженера, который раньше держал на ноутбуке отдельный клиент вроде Cyberduck или WinSCP, это означает на одну программу меньше. Для IT-директора это означает, что любой доступ к файлам сервера идёт через единую авторизацию платформы и попадает в общий журнал действий, а не происходит из-под личной учётной записи на стороннем приложении.
Раздел логов: единая лента из serverных журналов, Docker-контейнеров, Bitrix и 1С
Логи — модуль, который в большинстве компаний реализован хуже всего. Где-то стоит ELK или Loki, но обычно туда сваливается только часть данных, а половина источников живёт сама по себе. В COSCIO логи унифицированы вокруг единой таблицы и единого формата записи. Туда сходятся данные из journalctl по SSH с подключённых серверов, статусы и события Docker-контейнеров, события из Bitrix24 — изменения сделок, новые контакты, задачи, события из 1С через OData — движение документов, и события самого приложения — старты, перезагрузки, ошибки фоновых задач. Каждая запись имеет источник, уровень, временную метку, рабочее пространство, к которому она привязана. На странице логов есть фильтрация по источнику, по уровню, по серверу, по периоду, по подстроке. На странице конкретного сервера показана отфильтрованная лента только этого сервера. На странице Bitrix24 — отдельный блок логов CRM. Когда что-то ломается, не нужно открывать пять разных систем — достаточно одного запроса в общую ленту.
Инциденты — следующий слой над логами. Когда мониторинг или фоновая задача обнаруживает аномалию — упавший контейнер, недоступный сайт, истекающий сертификат, превышение порога ошибок в логах — заводится инцидент. У него есть статус (открыт, в работе, решён), приоритет, ответственный, привязка к серверу или сервису, история комментариев. Инциденты могут разбираться вручную, а могут — автоматически. В платформе есть подсистема remediation: для типовых проблем настраиваются playbooks, которые запускаются по триггеру. Например, если сайт начал отдавать 502 — попробовать перезапустить процесс приложения, если не помогло — поднять количество воркеров, если и это не помогло — эскалировать на дежурного инженера. Эти playbooks хранятся в платформе как код, версионируются, имеют сухой запуск для проверки. Это не замена SRE-команде с глубокой экспертизой, но это способ снять с инженеров рутинные операции, которые повторяются раз за разом и которые легко автоматизировать.
Раздел безопасности: CVE-сканирование зависимостей, threat intelligence, brute-force и remediation
Безопасность — один из самых нагруженных разделов. Сюда сходится несколько подсистем. Сканирование зависимостей: платформа знает, какие репозитории подключены, обходит их и анализирует package.json, requirements.txt, composer.json, go.mod, ищет известные уязвимости в базе CVE, показывает результат с разбивкой по проектам и уровню критичности. Это позволяет IT-директору видеть на одной странице, что у двух проектов критичные уязвимости в зависимостях, ещё у трёх — высокие, и спланировать обновление. Threat intelligence: платформа подписана на источники данных об актуальных угрозах и сопоставляет их с тем, что подключено в инфраструктуре. Если выходит новый эксплойт для конкретной версии nginx — и в инфраструктуре есть серверы с этой версией, появляется отдельное уведомление с пометкой критичности. Brute-force collector: платформа собирает с серверов попытки авторизации, агрегирует их по источникам, отмечает аномалии, показывает общую картину «кто к нам ломится и в какие порты». Remediation: автоматизированные сценарии реагирования — заблокировать IP в firewall, отозвать токен, выключить публичный доступ к сервису до выяснения, отправить алерт в Telegram дежурному.
AI-аналитика: разбор инцидентов и предсказания на базе Claude и GPT
AI-аналитика — раздел, в котором задействованы языковые модели Anthropic Claude и OpenAI GPT. Главная задача здесь — не «чат с искусственным интеллектом», а помощь оператору в разборе ситуаций. Когда заводится инцидент, AI может прочитать связанные логи, метрики, последние изменения в репозитории и выдать гипотезу, что произошло, с указанием, на основе каких данных он эту гипотезу строит. Это не заменяет инженера, но экономит ему первые двадцать минут — те самые двадцать минут, которые обычно уходят на «понять, в какую сторону вообще копать». Отдельная подсистема — предсказания: на базе исторических данных платформа пытается оценить, какой сервер скоро упрётся в диск, на каком будет дефицит RAM в течение недели, какая база приближается к лимиту по числу подключений. Это переводит реакцию с режима «уже горит» в режим «надо успеть до того, как загорится». Ключи для AI хранятся в настройках платформы и используются только тогда, когда администратор их явно задал — без явного согласия наружу ничего не уходит.
Сайт-мониторинг и публичная статус-страница идут вместе. Платформа умеет проверять доступность списка адресов с заданным интервалом, замерять время ответа, обнаруживать падения, заводить инциденты. На основе этого формируются две страницы статуса: внутренняя — для команды, с подробными метриками и причинами падений, и внешняя — публичная, доступная без авторизации, для клиентов. Внешняя статус-страница — это отдельный URL, на котором клиенты видят, какие сервисы работают, какие имеют проблемы, какие сейчас на плановом обслуживании. Окна обслуживания заводятся отдельно в настройках — задаётся период, затронутые сервисы, описание, и это сразу отражается на публичной странице.
Страница «Статус систем» с внутренней и публичной версиями
Затраты — раздел, который часто оказывается решающим при выборе подобной платформы. У среднего IT-департамента счета приходят из шести-семи мест: Timeweb, Hetzner, AWS, Cloudflare, домены, лицензии, SaaS-подписки. Сложить их в одну табличку — задача, которая обычно достаётся бухгалтеру или администратору, делается раз в квартал и не позволяет в моменте понять, куда уходят деньги. COSCIO собирает данные о затратах через API подключённых провайдеров, сводит их в одну таблицу с разбивкой по провайдеру, по проекту, по типу ресурса, по периоду. На странице затрат видно, например, что один сервер на Hetzner стоит дороже, чем три аналогичных на Timeweb, или что половина бюджета на AWS уходит на трафик S3, а не на сами серверы. Это даёт IT-директору материал для аргументированного разговора с бизнесом — где можно сэкономить, что нужно пересмотреть, на чём не стоит экономить, потому что цена компромисса выше.
Бэкапы — отдельный раздел с интерфейсом, которого обычно нет вообще ни в одной системе из стандартного стека. Платформа знает, у каких серверов настроены задания резервного копирования, куда складываются бэкапы (как правило, S3-совместимое хранилище), какой ретеншн, когда был последний успешный бэкап, какой размер. Если бэкап не сделался в положенное время или сделался с ошибкой — заводится инцидент. На странице конкретного бэкапа можно посмотреть историю успешных и неуспешных запусков, размер каждой копии, временные метки. Это превращает «у нас вроде есть бэкапы, скрипт стоит в кроне» в управляемый процесс, который виден, который проверяется, который можно восстановить и проверить — а не открывать в момент реального инцидента и обнаружить, что последний бэкап двухнедельной давности, а скрипт молча падал из-за изменившегося формата конфига.
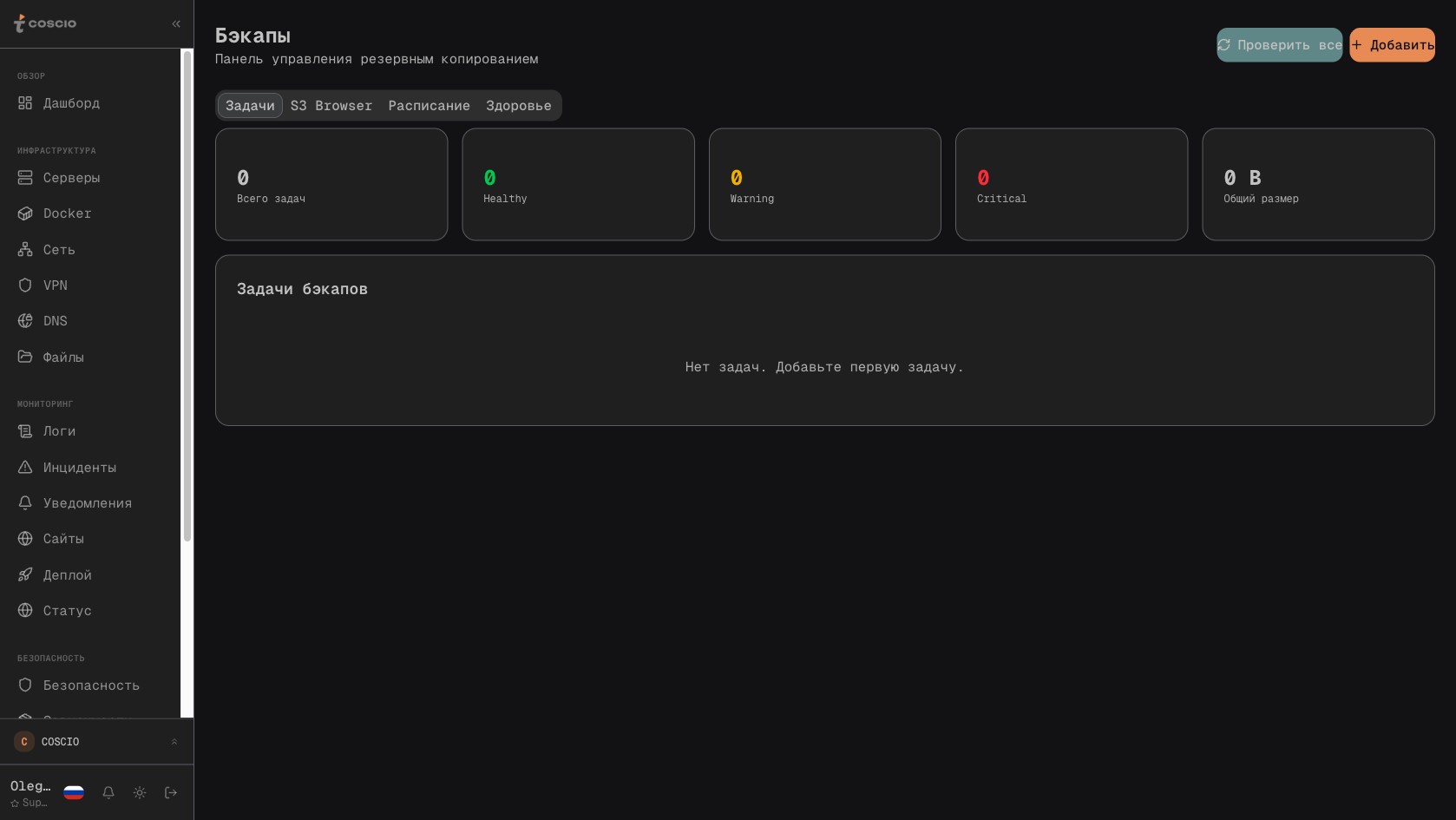
Раздел бэкапов: расписания, история, размеры и статусы по всем подключённым серверам
API-тестер, performance, traces — три инструмента, которыми пользуется уже не админ, а команда разработки, но они тоже встроены в общую платформу. API-тестер похож на упрощённую версию Postman, в которой коллекции запросов привязаны к рабочему пространству и доступны всей команде. Performance — обвязка вокруг Lighthouse и инструментов нагрузочного тестирования: для каждой страницы можно запустить отчёт и сравнить результаты по времени. Traces — приёмник OpenTelemetry, к которому можно отправлять трассировки из сервисов и смотреть, как запрос проходит через цепочку вызовов. Эти инструменты не претендуют заменить специализированные платформы вроде Honeycomb или Grafana Tempo, но для команды из пяти инженеров на десяти сервисах их более чем достаточно.
Почта, репозитории и бизнес-системы — слой интеграций. Почтовый раздел работает с Mailcow: показывает домены, ящики, очереди, blacklist. Раздел репозиториев умеет подключать GitHub, GitLab и Bitbucket, видит коммиты, pull requests, issues, прогоняет по ним же CVE-сканирование. Бизнес-системы — пожалуй, самая нестандартная часть платформы для подобных продуктов. Здесь есть встроенные модули для Bitrix24 (выгрузка сделок, контактов, задач, статусы воронок), для 1С через OData (номенклатура, контрагенты, документы), для AmoCRM (аналогично сделкам), для WordPress (мониторинг сайтов, обновления плагинов, состояние WP-Admin), для PayloadCMS (управление контентом и коллекциями). Это нужно потому, что в российской компании среднего размера IT-департамент так или иначе отвечает за работу этих систем — Bitrix24 падает чаще, чем хотелось бы, 1С требует постоянного внимания, WordPress становится воротами для атак. Иметь по каждой системе встроенный модуль, в котором видно, жива ли система, что в ней происходит, какие у неё свежие события — это сокращает время реакции и снимает необходимость держать отдельные dashboards.
Уведомления — поперечный слой, который пронизывает все модули. Каждое значимое событие — упавший сервер, истекающий сертификат, новый инцидент, успешный или неуспешный бэкап, аномалия в логах — может породить уведомление. Каналов доставки несколько: in-app через Server-Sent Events с колокольчиком в шапке интерфейса, e-mail через SMTP, Telegram через бот, SMS через sms.ru, VK MAX. Каждый пользователь в своих настройках сам выбирает, по каким типам событий он хочет получать уведомления и в какие каналы. Например, дежурный инженер настраивает Telegram + SMS на критичные инциденты, разработчик — только in-app для своих репозиториев, директор — еженедельный e-mail-дайджест по затратам и общему состоянию.
Если посмотреть на платформу с архитектурной стороны, в её основе лежит несколько ключевых решений, которые определяют, как она ведёт себя в продакшене. Первое — это монолитная архитектура Next.js на App Router. Не микросервисы, не отдельные backend и frontend, а единый full-stack монолит, в котором серверные компоненты обращаются к Prisma напрямую, а клиентские компоненты ходят в собственные API-роуты. Для платформы такого размера — около четырёхсот двадцати TypeScript-файлов, пятидесяти семи тысяч строк кода, двухсот девятнадцати API-обработчиков, сорока одного сервисного модуля, восьмидесяти трёх Prisma-моделей — монолит даёт ощутимое преимущество: одна сборка, одно развёртывание, одна точка для observability, нет необходимости в service mesh и оркестрации. Микросервисная архитектура была бы здесь архитектурным излишеством — те, кто разворачивает COSCIO у себя, не должны иметь kubernetes-кластер только ради того, чтобы запустить дашборд.
Второе важное решение — отдельный процесс для фоновых задач. Опрос провайдеров, сбор метрик, проверка сайтов, сбор логов, рассылка уведомлений, генерация AI-отчётов — это всё не должно блокировать обработку HTTP-запросов. Поэтому в платформе используется BullMQ как очередь задач поверх Redis, и есть отдельный worker-процесс, который запускается systemd-юнитом независимо от основного web-процесса. Всего настроено девятнадцать очередей под разные классы задач — метрики, логи, healthcheck, алерты, мониторинг сайтов, синхронизация Bitrix, синхронизация 1С, проверки CI/CD, сетевые сканы, проверки Docker, очистка устаревших данных, обновление DNS, продление SSL, бэкапы, синхронизация VPN, обновление затрат, прогон performance, сканы зависимостей, проверки безопасности. Каждая очередь имеет своё расписание и свою политику ретраев. Расписания не зашиты в код, а хранятся в таблице настроек и редактируются администратором через интерфейс — кому-то достаточно опрашивать метрики раз в пять минут, а кому-то нужны секундные интервалы.
Третье решение — multi-tenant архитектура с концепцией «Рабочее пространство». В терминологии кода это Organization, в интерфейсе — Workspace. Один и тот же пользователь может быть участником нескольких рабочих пространств: например, у IT-аутсорсера это пять разных клиентов, у внутреннего IT-департамента — это «продакшн», «стейджинг», «личные эксперименты». У каждого рабочего пространства собственные интеграции, собственные подключения провайдеров, собственные пользователи с разными ролями, собственная подписка. Переключение между пространствами идёт через cookie и специальный переключатель в нижней части боковой панели. Уникальность интеграций гарантирована на уровне базы: в одном рабочем пространстве нельзя добавить два аккаунта Timeweb Cloud или два экземпляра Bitrix24 — потому что это создавало бы неоднозначность, которой не должно быть.
Четвёртое — строгая последовательность SSH-команд к одному серверу. Если запустить параллельно две операции на одной машине — например, рестарт nginx и одновременно проверку диска — это с большой вероятностью даст битый вывод или путаницу с pty. Платформа строит очередь команд для каждого сервера и обрабатывает их одну за другой, не запуская следующую, пока не завершилась предыдущая. Все параметры команд валидируются регулярными выражениями и проходят shell-escaping, чтобы исключить инъекции через имена файлов, пути или произвольные пользовательские строки. SSH-ключи и пароли от баз данных шифруются в хранилище алгоритмом AES-256-GCM с ключом, который выводится из секрета через scrypt и кешируется в памяти процесса — на диске и в дампе базы открытых секретов нет.
Пятое — концепция Module Toggle. Поскольку модулей в платформе много, и далеко не всем нужны все, в настройках рабочего пространства каждый модуль можно включить или выключить. Если у компании нет 1С — модуль 1С отключается и не занимает место в боковой панели. Если нет своего DNS-провайдера — выключается DNS. При этом отключить модуль, в котором уже накоплены данные, нельзя — сначала данные нужно удалить или экспортировать. Это защищает от ситуации, когда администратор случайно скрывает модуль, и пользователи перестают видеть существующие записи, думая, что они удалились.
Настройки платформы: тарифные планы, валюты, ключи AI, ретеншены, пороги, расписания
Шестое — настройки в базе, а не в переменных окружения. В большинстве систем настройки разбиты на две неравные части: что-то лежит в .env, что-то — в админке. Это плохо тем, что менять .env-параметр в проде означает рестартовать процесс, и значит — кратковременный простой. Платформа COSCIO построена иначе: в .env остаются только инфраструктурные параметры — подключение к базе, секреты NextAuth, ключи провайдеров OAuth, домен приложения. Всё остальное — ключи AI, конфигурация платёжных провайдеров, курсы валют, цены тарифных планов, расписания фоновых задач, периоды хранения данных, пороги для health-проверок, конфигурация VPN, ключи Cloudflare и Mailcow, токены ChatOps — хранится в таблицах базы данных. Часть из них — глобальные настройки администратора, доступные только пользователю с ролью superadmin. Часть — настройки уровня рабочего пространства, которые управляются владельцем этого пространства. Это значит, что администратор может поменять курс рубля к доллару прямо из интерфейса, без редактирования файлов на сервере, и изменение применится в течение минуты.
Седьмое — fluid design-system, которая работает на любых экранах. Все размеры — шрифты, отступы, контейнеры — масштабируются плавно через CSS-функцию clamp от 375 пикселей по ширине до 1920. На экранах больше 1920 пикселей содержимое центрируется и не растягивается до бесконечности, что для дашбордов критично — иначе текст «расползается» по 4K-монитору, и читать его становится тяжело. Media-запросы используются только там, где меняется сам layout — например, сетка из четырёх колонок превращается в одну на узком экране. Никаких жёстко прописанных размеров шрифта или отступов в коде нет — есть только токены дизайн-системы, что упрощает поддержку и гарантирует единый визуальный язык по всему интерфейсу. Основной шрифт — Geist Mono: это сознательный выбор, чтобы интерфейс выглядел инженерно, а не маркетингово, и чтобы код, IP-адреса, идентификаторы, команды читались одинаково хорошо в любом месте.
Восьмое — интернационализация. Платформа поддерживает шесть языков: английский, русский, французский, итальянский, испанский, китайский. По умолчанию открывается русский — потому что основной целевой рынок российский. Все строки в интерфейсе вынесены в файлы переводов, и изменение одной строки на одном языке обязательно требует синхронизации остальных пяти — для этого есть отдельный инструмент сверки ключей. На стороне CMS, из которой подгружается контент блога и страниц, локализация поддержана на том же наборе языков с тем же дефолтом. Этот же подход распространяется и на форматирование чисел, дат, валют — везде, где данные показываются пользователю, формат выбирается по текущей локали, а не зашит в коде. Для команд, в которых работают сотрудники из разных стран — что для российского IT-сектора давно стало нормой — это снимает мелкое, но постоянное трение, когда один человек видит дату в формате месяц-день-год, а другой ожидает день-месяц-год.
Девятое — аутентификация поверх NextAuth с поддержкой нескольких провайдеров. Войти в платформу можно по логину и паролю, через Google, через GitHub или через Yandex. Это покрывает большинство сценариев: корпоративный e-mail с собственным паролем для админов, Google или GitHub для разработчиков, у которых уже есть рабочие аккаунты, Yandex для тех, кто работает с Яндекс.Почтой как с основным ящиком. Сессии хранятся в JWT, в котором сразу содержится список всех рабочих пространств пользователя — это позволяет переключаться между ними без повторной авторизации. Роли разделены на уровни: внутри рабочего пространства есть собственная роль (владелец, администратор, участник), а на уровне всей платформы — отдельная роль superadmin для тех, кто управляет инсталляцией в целом, видит настройки сервера, тарифные планы, ключи интеграций административного уровня. Это разделение важно, потому что в self-hosted сценарии часто IT-директор компании — это не тот же человек, что владелец рабочего пространства внутри платформы; первый отвечает за инфраструктуру, второй — за конкретный проект.
Естественно возникает вопрос — а чем это отличается от существующих платформ? Grafana — это про графики и дашборды, но в ней нельзя перезагрузить сервер, нельзя создать инцидент, нельзя выпустить VPN-конфиг, нельзя автоматически среагировать на проблему. Datadog — мощная платформа с разнообразными возможностями, но это SaaS на чужой инфраструктуре, с ценником в долларах, с экспортом данных наружу и без интеграций с российскими бизнес-системами. Zabbix — классическая система мониторинга, но без современного интерфейса, без AI-разбора инцидентов, без модулей для бизнес-систем, без статус-страницы из коробки. Jira + Confluence закрывают инциденты и документацию, но никак не связаны с инфраструктурой и требуют ручной синхронизации. Bitrix24 даёт CRM, но никак не помогает с серверами. Каждый из этих продуктов хорош в своей нише, но ни один не закрывает задачу единого портала IT-директора целиком — а связка из десяти продуктов разной природы создаёт ровно ту проблему, ради которой COSCIO существует.
COSCIO позиционируется как self-hosted решение — устанавливается на собственный сервер компании, данные не уходят к стороннему провайдеру, всё под контролем заказчика. Это критично для компаний, которые работают с персональными данными по 152-ФЗ, для государственных и окологосударственных структур, для финансовых организаций, для любых случаев, когда передача оперативных данных в зарубежный SaaS — это юридический или политический риск. Биллинг в платформе поддерживает Stripe для зарубежного контура, Yukassa и Tinkoff — для российских платежей в рублях. Валюты тоже хранятся в настройках и пересчитываются по курсу, который администратор задаёт сам или подтягивает автоматически.
Целевая аудитория продукта — это компании с пятью-пятидесятью серверами, в которых есть одна-две команды разработки, есть классический российский бизнес-стек (Bitrix24, 1С, AmoCRM, WordPress), и есть совершенно конкретная боль: слишком много инструментов, слишком много логинов, слишком много мест, где надо смотреть, чтобы понять состояние инфраструктуры. Это не продукт для enterprise-компаний с собственным SRE-отделом, у которых уже есть отлаженный стек на базе Datadog или собственной разработки — им платформа COSCIO ничего нового не даст, и переход с привычного стека на новый будет дороже выгоды. И это не продукт для одиночек с одним VPS — для такого размера достаточно встроенных инструментов провайдера и пары bash-скриптов. Платформа имеет смысл там, где количество переходит в качество: когда систем становится так много, что их взаимодействие важнее, чем функции каждой по отдельности.
Отдельного внимания заслуживает то, как платформа выстраивает аудит-след. Каждое действие пользователя, каждая автоматическая операция, каждый запуск playbook оставляет запись в системном журнале с указанием, кто, когда, в каком рабочем пространстве и над каким объектом выполнил действие. Это не отдельная функция «логирование», которую можно включить или забыть, а встроенный поведенческий контракт всей платформы. Для IT-директора это означает, что в любой момент можно проследить цепочку событий до конкретного человека и конкретного решения. Для аудита внешнего — это материал, который не приходится восстанавливать по обрывкам логов разных систем, и который имеет согласованный формат, потому что писался одним приложением.
Что касается дальнейшего развития, ключевая ставка делается на три направления. Первое — расширение списка поддерживаемых провайдеров и интеграций. Архитектура с абстракцией CloudProvider и единым контрактом интеграций позволяет добавлять новые источники данных без переписывания ядра — нужно реализовать интерфейс, и новый провайдер появляется во всех релевантных модулях. Второе — углубление AI-функциональности: не просто разбор инцидентов, но активный помощник, который может предложить изменение конфигурации, обнаружить аномалию до того, как она перейдёт в инцидент, сравнить производительность двух версий приложения. Третье — фокус на российский рынок: интеграции с локальными провайдерами и сервисами, поддержка отечественных мессенджеров для уведомлений, соответствие требованиям регуляторов, цены в рублях, документация и поддержка на русском.
Когда технический департамент перестаёт прыгать между десятком вкладок и получает единое окно, в котором видна инфраструктура целиком, меняется не только время на рутинные операции. Меняется сам способ принятия решений. Директор видит на одном экране состояние всех серверов, расходы по всем облакам, открытые инциденты, уровень безопасности, состояние бизнес-систем — и может задавать вопросы более высокого порядка, чем «а работает ли у нас почта». Инженеры перестают тратить часы на поиск нужной системы в закладках браузера и могут думать про настоящие задачи. Знание перестаёт жить в головах конкретных людей и фиксируется в платформе как набор интеграций, настроек и playbooks, который переживает уход любого инженера. Бизнес перестаёт быть слепым в отношении IT и получает понятную картину: что есть, сколько стоит, что под угрозой, что требует внимания. Это и есть та трансформация, которую закладывает в продукт идея единого портала IT-директора — не «ещё один дашборд», а смена операционной модели всего технического департамента.