Идея, что инфраструктура средней компании помещается в один личный кабинет одного провайдера, окончательно перестала соответствовать реальности году к двадцать третьему, а к двадцать шестому превратилась в анахронизм. Стандартный набор сервисов, без которых бизнес даже среднего звена в России сегодня не работает, физически не умещается на одном-двух VPS — он требует распределённой инфраструктуры, и эта распределённость возникает не по выбору архитектора, а по совокупности внешних обстоятельств, каждое из которых тянет в свою сторону. Один сервер уходит в локацию ru-3 потому что там лучше связность с клиентскими сетями московского региона, второй — в ru-1 потому что туда переехала база данных после миграции с устаревшего железа, третий — в nl-1 потому что российские IP-адреса блокируются нужным внешним API, четвёртый вообще оказывается у другого провайдера потому что у этого провайдера дешевле трафик. И через год-полтора такой эволюции компания, начинавшая с одной машины и одного кабинета, оказывается с пятнадцатью серверами в трёх-четырёх облаках, и человек, который должен это всё поддерживать, открывает с утра пятнадцать вкладок и пытается понять, где что упало.
Эта картина повторяется настолько систематически, что её перестали даже обсуждать — она стала фоном, новой нормальностью, к которой все привыкли как к плохой погоде. Между тем именно она порождает большую часть скрытых издержек на администрирование: время, которое тратится не на работу, а на навигацию между интерфейсами разных провайдеров, на сверку метрик из несовместимых форматов, на ручное составление сводных отчётов, на попытки найти в куче кабинетов сервер, который вчера тормозил и до сих пор тормозит, но непонятно где именно. Если посчитать, сколько часов в неделю системный администратор средней компании тратит на эту прокладку между разными UI, цифра получается неприличная — по разным оценкам от десяти до двадцати процентов рабочего времени уходит просто на то, чтобы понять, что вообще происходит в собственной инфраструктуре. И это при том, что сами действия, которые в результате этой навигации совершаются, занимают минуты — основное время съедает поиск, переключение контекста и сверка.
Подход, на котором построен COSCIO, исходит из довольно простой посылки: если у компании уже есть N провайдеров и она не собирается ни одного из них выкидывать, имеет смысл сделать так, чтобы все они выглядели одинаково — и для глаз человека, который смотрит на экран, и для кода, который этими серверами управляет. Достичь этого можно только одним способом — построить абстракцию поверх разнородных API, скрыть различия за общим интерфейсом и оставить специфику провайдера ровно там, где она действительно нужна, не пуская её наверх, в пользовательский слой. Архитектурно это решение выглядит как папка `src/lib/providers/` с одним интерфейсом `CloudProvider` и пятью его реализациями — Timeweb Cloud, Hetzner, AWS, DigitalOcean и custom-SSH. Интерфейс содержит ровно тот набор операций, который реально нужен IT-директору на ежедневной основе: получить список серверов, получить детали конкретного сервера, снять метрики, перезагрузить, включить, выключить и выполнить SSH-команду. Всё остальное — частные случаи этих базовых действий.
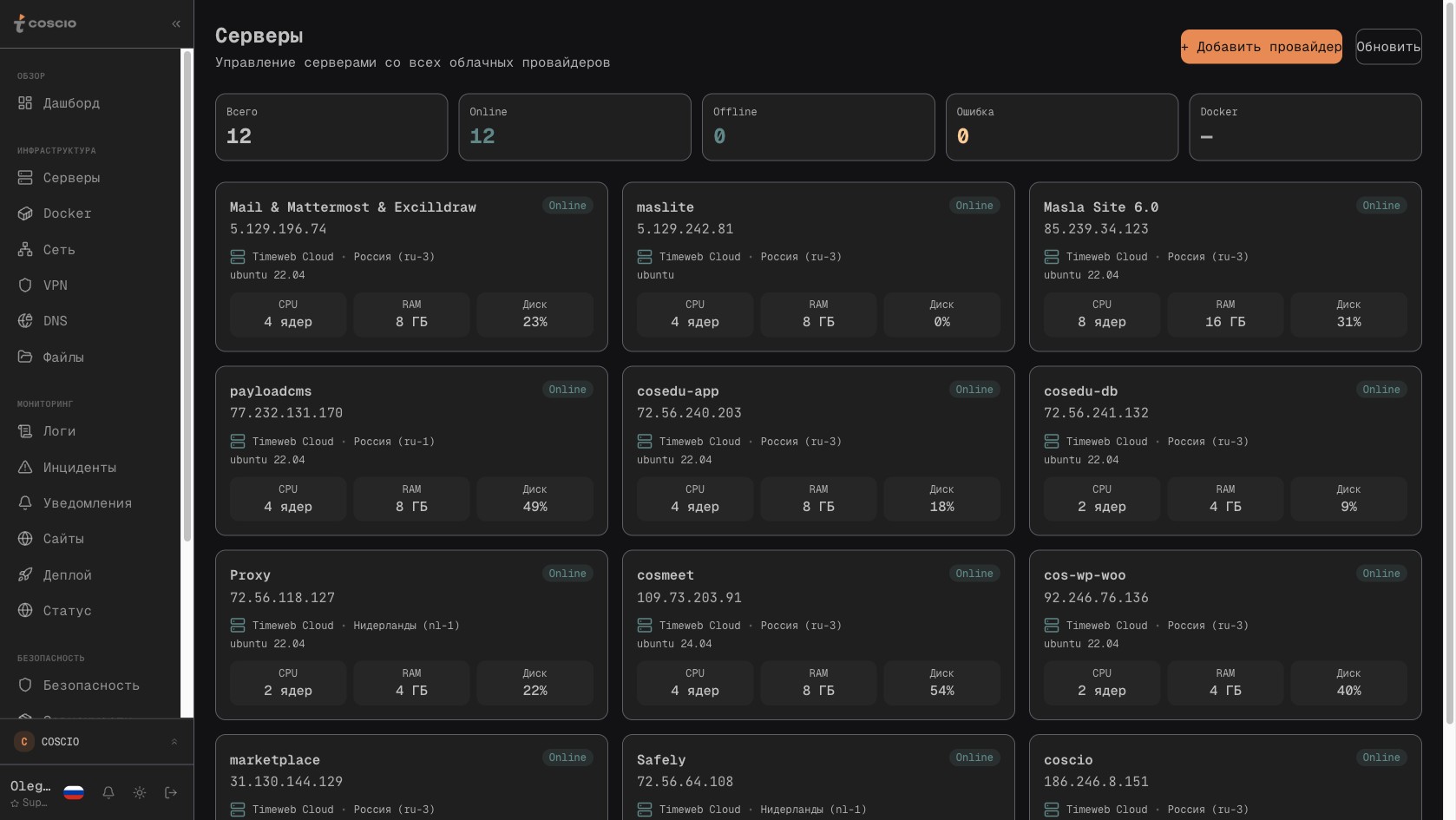
Список из двенадцати реальных серверов разных провайдеров в одном интерфейсе COSCIO — независимо от того, где физически живёт машина, она показана одинаково
То, что на скриншоте видны двенадцать серверов разных назначений, расположенных в трёх локациях одного провайдера, — это снимок текущего состояния. Архитектурно ничего не мешает рядом с серверами Timeweb отображаться машинам Hetzner из Финляндии, инстансам AWS из ирландского региона и dedicated-серверам, к которым доступ есть только по SSH. Реализации провайдеров инкапсулируют разговор с их API и нормализуют ответ к общему формату ServerInfo и ServerMetrics — список колонок в таблице всегда один и тот же, статус серверов всегда показывается одинаковыми бейджами, локация выводится в одном и том же столбце независимо от того, как её называет конкретный провайдер во внутреннем формате. Если Timeweb отдаёт регион в формате `ru-3`, а Hetzner — в формате `nbg1`, на уровне интерфейса оба превращаются в человекочитаемый ярлык, и человек, который смотрит на список, не должен помнить, что у одного провайдера регионы называются так, а у другого — этак.
Внутри хранения конфигов провайдеров действует строгое правило: один тип провайдера на одно рабочее пространство. Реализуется это уникальным составным ограничением `@@unique [orgId, provider]` в таблице `cloud_provider_configs` — нельзя добавить в один workspace два аккаунта Timeweb или два аккаунта Hetzner, потому что это размывает понятие принадлежности сервера. Если компания держит у одного провайдера несколько проектов разных команд и эти команды должны быть друг от друга изолированы, правильный паттерн — заводить отдельные workspace под каждую команду, и тогда каждый из них подключает свой аккаунт того же провайдера со своими ключами. Workspace в коде называется Organization, в интерфейсе — рабочее пространство, и один пользователь может одновременно состоять в нескольких таких пространствах, переключаясь между ними через свитчер в нижнем левом углу sidebar.
Credentials, которые требуются для разговора с API провайдера, шифруются на уровне базы данных алгоритмом AES-256-GCM. Ключ шифрования формируется из двух переменных окружения — `DB_ENCRYPTION_KEY` и `DB_ENCRYPTION_SALT` — через функцию scrypt с кэшированием результата в области видимости модуля, чтобы не пересчитывать тяжёлый KDF на каждый запрос. Сами зашифрованные blob'ы лежат в БД и расшифровываются только в момент непосредственного обращения к API провайдера, никогда не выгружаются в логи и не передаются в клиентский слой. Это особенно важно для сценариев, когда у компании есть несколько команд с разными уровнями доступа: разработчик, у которого есть учётка в COSCIO, может управлять серверами, не зная при этом ни одного токена ни одного провайдера, — токены хранятся централизованно и применяются автоматически, без необходимости транслировать их через рабочие места.
Резолвинг провайдера происходит через `registry.ts` с двумя ключевыми функциями: `getProvider(configId)` возвращает инстанс реализации для конкретной записи в `cloud_provider_configs`, а `getOrgProviders(orgId)` — все провайдеры, доступные в данном рабочем пространстве. Эта схема позволяет в одном UI-вызове, например, при рендеринге страницы со списком серверов, обойти все провайдеры workspace, у каждого вызвать `listServers()`, склеить результаты в единый список и отдать его на фронт. Если у компании в одном workspace подключён Timeweb с восемью серверами, AWS с тремя инстансами и dedicated-сервер у локального хостера через custom-SSH, на странице окажется двенадцать строк, и пользователь, который на неё смотрит, может вообще не знать, что эти двенадцать машин физически живут у трёх разных контрагентов. Для него это просто его инфраструктура.
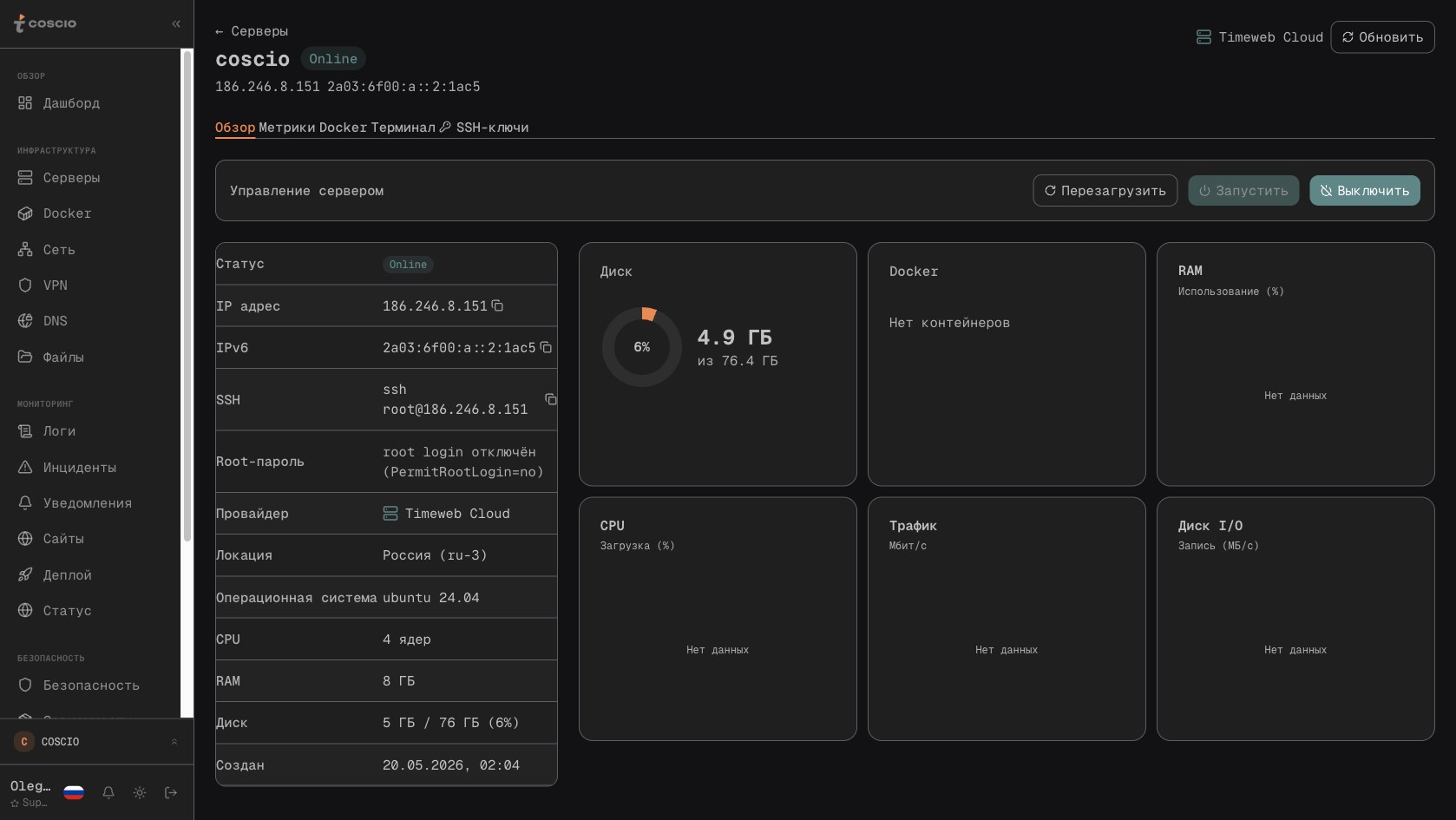
Детальная карточка сервера со всеми виджетами — независимо от провайдера, разворот всегда одинаковый
Стоит отдельно обсудить, почему такая абстракция вообще работает, потому что любая попытка натянуть единый интерфейс на разные API сталкивается с одной и той же проблемой: API провайдеров отличаются не только в синтаксисе, но и в семантике. У одного провайдера операция перезагрузки означает graceful shutdown с последующим стартом, у другого — жёсткий reset. У одного метрики CPU отдаются в процентах с разбивкой по ядрам, у другого — суммарным числом загрузки, у третьего вообще не отдаются и приходится получать их через SSH-вход и парсинг `/proc/stat`. В COSCIO эта неоднородность решается на уровне реализаций — каждая реализация знает специфику своего провайдера и приводит результат к нормализованному виду. Скажем, для Timeweb известно, что у их публичного REST API есть устойчивая проблема с метриками CPU — они не всегда возвращаются, особенно для свежесозданных машин или после перезагрузки. Реализация Timeweb-провайдера в случае пустого ответа делает fallback на SSH-команду, которая читает `/proc/stat`, парсит первую строку, считает дельту между двумя замерами и возвращает корректное значение загрузки. Для пользователя это прозрачно — он видит график CPU и не подозревает, что данные пришли двумя разными путями.
Сбор метрик организован двухуровневой схемой, и это не оптимизация ради оптимизации, а вынужденное решение, продиктованное масштабом. Если для одного-двух серверов можно позволить себе хранить замеры каждые тридцать секунд за бесконечный период, для двадцати серверов это означает миллион семьсот тысяч записей в сутки, пятьдесят миллионов в месяц и шестьсот миллионов в год — и это только метрики CPU, без памяти, диска и сети. Запросы к такой таблице деградируют, индексы пухнут, бэкапы становятся неподъёмными. Поэтому в COSCIO живут два слоя метрик: оперативный с разрешением тридцать секунд и retention семь дней, и агрегированный почасовой с retention девяносто дней. Оперативный слой нужен для диагностики "что происходит прямо сейчас" — если сервер начал тормозить, открывается график за последний час с тридцатисекундным разрешением, и видно ровно ту секунду, когда нагрузка пошла вверх. Агрегированный слой нужен для долгосрочных наблюдений — посмотреть, как менялась загрузка за месяц, увидеть еженедельный паттерн, оценить, не пора ли увеличивать ресурсы. На каждой почасовой записи хранятся два значения — среднее и максимальное за час, — что позволяет не терять пики при усреднении.
Сбором метрик занимается отдельный воркер на BullMQ, который живёт как самостоятельный процесс рядом с основным Next.js-приложением. Это сделано принципиально — никакая длительная работа не выполняется в request-cycle веб-сервера, потому что это блокировало бы пул соединений и приводило бы к таймаутам интерфейса. BullMQ-воркер запускается через `worker-entrypoint.ts`, держит соединение с Redis, обрабатывает девятнадцать очередей, среди которых есть очередь метрик. Внутри неё крутится repeatable job, расписание которого читается из таблицы `settings` — администратор может через UI на странице `/settings/platform` поменять интервал сбора, не пересобирая код и не перезапуская приложение. Дефолт — каждые тридцать секунд для оперативных метрик, каждый час — для агрегации. Кроме метрик в воркере живут очереди логов, проверок здоровья контейнеров, алертов, проверок сайтов, синхронизации с Bitrix24 и 1С, CI/CD, сети, Docker health, SSL, бэкапов, VPN, биллинга, performance и сканирования зависимостей — всего девятнадцать.
Вкладка Метрики на странице сервера — двухуровневое хранение позволяет одновременно показывать высокое разрешение за час и долгосрочный тренд за месяц
Отдельной темой является обращение к серверам по SSH — потому что это операция, в которой ошибка стоит дороже всего и при которой нарушение базовых правил приводит к самым неприятным последствиям. В COSCIO принято несколько архитектурных решений, которые на первый взгляд могут показаться чрезмерной осторожностью, но за каждым стоит история конкретного инцидента, и без них система не была бы пригодна для эксплуатации. Первое правило: SSH-команды к одному серверу выполняются строго последовательно. Никаких параллельных подключений, даже если кажется, что они независимые, даже если запросов всего два. Причина в том, что современные fail2ban и стандартные настройки sshd по `MaxStartups` рассматривают пачку одновременных входов как потенциальную брутфорс-атаку и могут забанить IP-адрес сервиса на длительное время. Для парка из пятнадцати серверов один забаненный IP означает потерю мониторинга на всех пятнадцати — и не на пять минут, а на сутки. Поэтому очередь SSH-операций упорядочена на уровне приложения, и даже если десять разных пользователей в один и тот же момент решат перезагрузить один и тот же сервер, их запросы выстроятся в строгую цепочку.
Второе правило касается валидации параметров. Любые входные данные, которые попадают в SSH-команду — имя пользователя, путь к файлу, аргумент к утилите, — проходят через строгие регулярные выражения и shell-escape. Это защита не от внешнего злоумышленника, который и так не достанет до интерфейса без аутентификации, а от случайной инъекции при копипасте — когда оператор скопировал из мессенджера команду с кавычками не того типа или с переводом строки в середине, и эта команда уехала на сервер с непредсказуемыми последствиями. Регексы отсекают всё, что не входит в ожидаемый формат, а shell-escape экранирует то, что прошло первый фильтр. Это два слоя защиты, и оба обязательны.
Третье правило — никаких паролей. Аутентификация на каждом сервере организована парой "ключ плюс TOTP", и оба фактора уникальны для каждой машины. У каждого сервера свой SSH-ключ, который хранится в таблице `ServerPrivateAccess` зашифрованным тем же AES-256-GCM, что и credentials провайдеров. Утечка ключа одного сервера не даёт ничего на других серверах. Если по какой-то причине ключ оказывается скомпрометирован — например, лэптоп с доступом к админке потерян, — достаточно перегенерировать ключ на одной машине, не трогая остальные. Это принципиально отличается от схемы "один ключ на все серверы", которая исторически встречается во многих компаниях и которая каждый раз превращает потерю ноутбука в трёхдневный ремонт инфраструктуры.
Четвёртое правило — все секреты и ключи, относящиеся к одному рабочему пространству, изолированы от других. Если в системе зарегистрированы две команды и каждая работает со своим набором серверов, ключи доступа одной команды физически не доступны для запросов от другой — фильтр по `orgId` проставляется на уровне Prisma-запросов, и обойти его без перезаписи кода невозможно. Это особенно важно для подрядных моделей, когда одна команда сопровождает несколько клиентов и должна гарантировать им, что данные одного клиента не утекут к другому. В COSCIO это гарантия архитектурная, а не процессная — её нельзя обойти, забыв проставить чекбокс в настройках.
Отдельный раздел заслуживает разговор о приватных сетях — то есть о том способе связать серверы между собой, который не выходит в публичный интернет и не зависит от внешних маршрутизаторов. Многие провайдеры — в первую очередь Timeweb, но также Hetzner и AWS — предоставляют возможность создать частную сеть между виртуальными машинами одного аккаунта, с собственной адресацией, с собственными маршрутами, недоступную из публичного интернета. Если в парке есть, скажем, веб-сервер и сервер базы данных, имеет смысл связать их именно по такой сети — это и быстрее, и безопаснее, чем гонять трафик через публичные IP с тунелированием. COSCIO видит эти сети, отображает их на странице раздела `/network`, показывает, какие серверы в какой сети состоят, какие адреса им присвоены, какие маршруты прописаны. Управление сетями — создание новой, добавление серверов в существующую, удаление — выполняется через тот же CloudProvider-интерфейс, что и операции с самими серверами. И снова: то, что у Timeweb приватная сеть называется одним именем, а у Hetzner — другим, на уровне UI не имеет значения, всё приводится к общему термину.
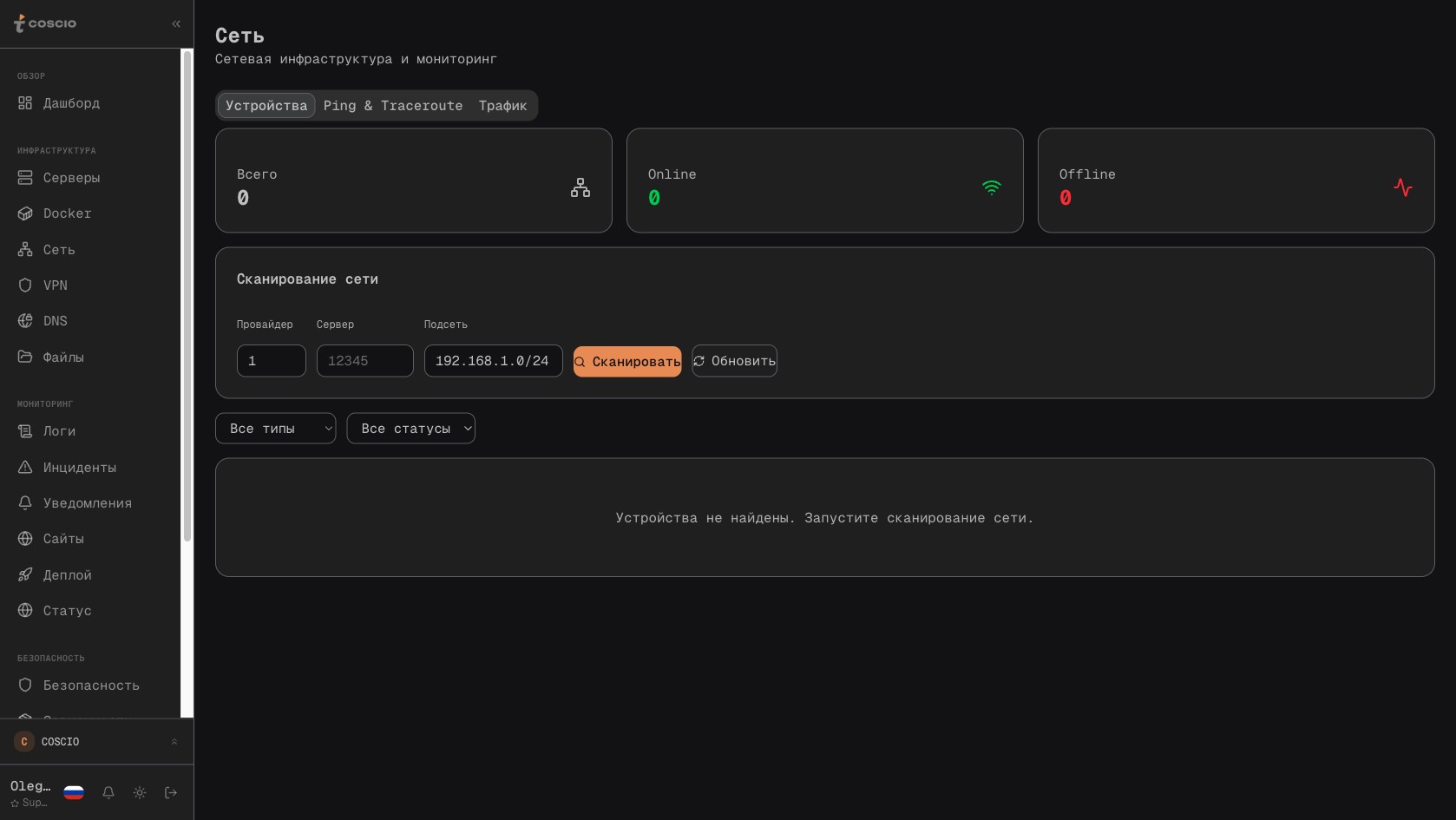
Раздел Сеть — приватные сети между серверами одного рабочего пространства, с собственной адресацией и без выхода в публичный интернет
Возвращаясь к теме рабочих пространств, стоит подробнее обсудить, как это работает на практике в компании, где несколько команд занимаются разными проектами. Типичный сценарий: одна команда поддерживает корпоративный B2B-портал на Bitrix, другая — несколько маркетинговых сайтов на собственной CMS, третья — почтовый и коммуникационный стек. У каждой команды свой набор серверов, свои интеграции с внешними сервисами, свои наборы доступов. В COSCIO для такой ситуации заводится три отдельных рабочих пространства, в каждом — свои подключения к провайдерам, свои серверы, свои настройки уведомлений и алертов. Один человек, который, скажем, является техническим директором и должен видеть всё, состоит в членстве всех трёх пространств и переключается между ними через свитчер в нижней части sidebar. В каждый момент он видит ровно одно пространство — серверы, метрики, инциденты, статистику только этого workspace, — что снижает когнитивную нагрузку и предотвращает случайные действия не в том контексте. Если бы все серверы были смешаны в одной плоской таблице, риск нажать `reboot` не на том сервере был бы значительно выше.
Изоляция между рабочими пространствами проходит насквозь через всю систему, не только через интерфейс. На уровне Prisma-схемы практически каждая модель домена ссылается на `organizationId`, и запросы фильтруются по текущему workspace через сессию. Невозможно случайно вытащить серверы одного workspace при запросе из контекста другого — это не контролируется правилами в коде, это контролируется самой структурой данных. Уникальные ограничения вроде `@@unique [orgId, type]` на таблице интеграций гарантируют, что в одном рабочем пространстве не появится два аккаунта одного типа — например, нельзя одновременно подключить два разных Telegram-бота для уведомлений, потому что это превратило бы алертинг в кашу. Если требуется иметь два разных Telegram-канала для разных команд — это делается через два разных рабочих пространства.
Теперь имеет смысл проговорить несколько сценариев, в которых единое окно управления парком разрозненных серверов даёт измеримый выигрыш. Первый и самый частый — массовая проверка состояния SSL-сертификатов. У средней компании с парком в пятнадцать серверов на этих серверах живёт обычно от двадцати до пятидесяти доменов — основной корпоративный сайт, маркетинговые лендинги, поддомены под промо-кампании, API-эндпоинты, технические домены типа `status.`, `wiki.`, `mail.`. У всех этих доменов есть SSL-сертификаты, у всех есть срок действия, и каждый из них может протухнуть в самый неподходящий момент. В разрозненной инфраструктуре отслеживание этих сертификатов превращается в отдельную задачу, под которую часто заводят отдельный мониторинговый сервис. В COSCIO раздел `/dns` и связанный с ним сервис SSL-сертификатов обходят все домены всех серверов всех провайдеров одного рабочего пространства и формируют единый список с цветовыми бейджами — зелёным помечаются сертификаты, до конца действия которых больше тридцати дней, жёлтым — от тридцати до семи, красным — меньше семи. Один взгляд на эту страницу заменяет двадцать переходов в разные кабинеты.
Второй сценарий — обновление пакетов на серверах одной локации. Допустим, в инфраструктуре известна уязвимость в конкретной версии OpenSSL, и нужно обновить пакет на всех серверах, где он установлен. Без единого окна это превращается в обход всех машин по очереди — зайти, проверить версию, обновить, перезагрузить если нужно, проверить, что всё поднялось. Для десяти серверов это полдня работы; для двадцати — день. В COSCIO такая задача решается через массовое SSH-выполнение: интерфейс позволяет выбрать чекбоксами серверы по фильтру — например, все серверы Timeweb в локации ru-3, — и выполнить на них одну и ту же команду или последовательность команд. Каждый сервер выполняется последовательно, с записью результата в журнал, с возможностью видеть прогресс в реальном времени. Если на каком-то сервере команда упала, она помечается красным, остальные продолжают выполняться. Полдня работы превращаются в десять минут — и это при том, что под капотом строго соблюдается правило "не параллелить SSH к одному серверу", потому что параллельность по серверам безопасна, а параллельность внутри сервера — нет.
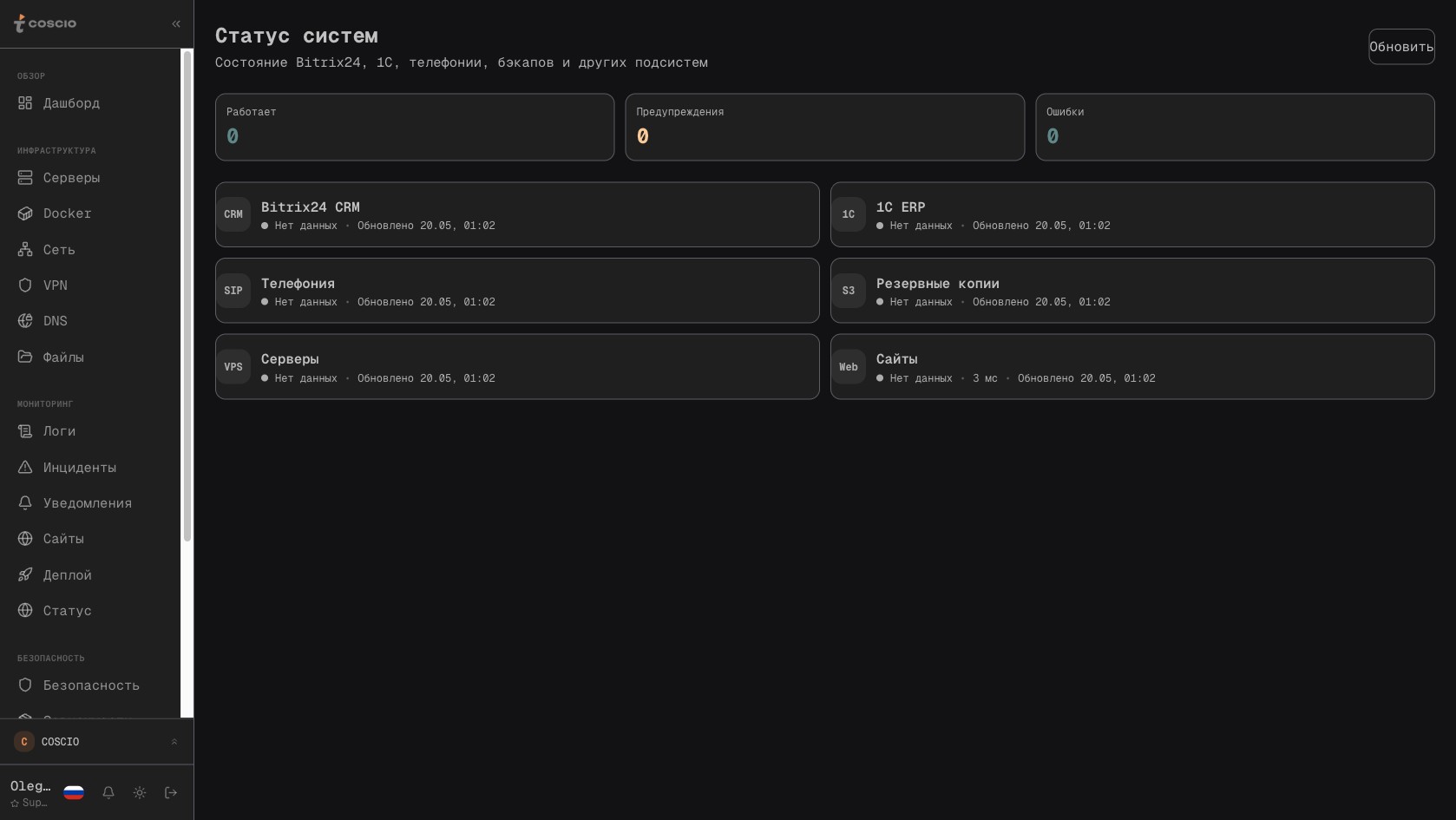
Раздел Статус — сводное состояние всей инфраструктуры с разбивкой по компонентам
Третий сценарий — формирование сводного отчёта об оборудовании. Раз в квартал у среднего CTO возникает задача: посчитать, сколько компания тратит на инфраструктуру, что куда уходит, нет ли там лишнего. В разрозненной инфраструктуре эта задача решается через выгрузку CSV из каждого кабинета, ручную сводку в Excel и попытку склеить нестандартизированные форматы. В COSCIO раздел `/costs` агрегирует данные от всех подключённых провайдеров одного workspace — Timeweb, Hetzner, AWS, DigitalOcean — и показывает разбивку по серверам, по локациям, по типам ресурсов. Можно увидеть, что условный сервер в локации nl-1 обходится в шесть тысяч рублей в месяц, при этом загружен на семь процентов CPU и тридцать процентов памяти — явный кандидат на даунгрейд. Можно увидеть, что суммарные расходы на маркетинговые сайты составляют двадцать тысяч в месяц, и сопоставить это с их посещаемостью. Без агрегации эти выводы не делаются — каждый счёт лежит в своём кабинете в своём формате, и собрать из них общую картину занимает день.
Четвёртый сценарий, к которому стоит вернуться — диагностика проблемы. Что происходит, когда пользователь жалуется, что сайт тормозит. В разрозненной инфраструктуре администратор должен сначала вспомнить, на каком сервере живёт этот сайт, потом залезть в кабинет соответствующего провайдера, посмотреть метрики, потом, если они не выявили проблему, зайти по SSH, посмотреть логи, проверить нагрузку процессов. На каждом шаге — переключение контекста, на каждом шаге — потеря времени. В COSCIO эта последовательность сжимается: открывается страница сервера, на ней одновременно видны метрики последнего часа в высоком разрешении, текущий статус ключевых сервисов, последние записи системного журнала, список запущенных Docker-контейнеров с их health-статусами. Если проблема в CPU, она видна на графике. Если в памяти — на графике. Если в логах — в окне журнала. Если в зависшем контейнере — в списке Docker. Не нужно переключать вкладки и сверять источники, всё в одном экране.
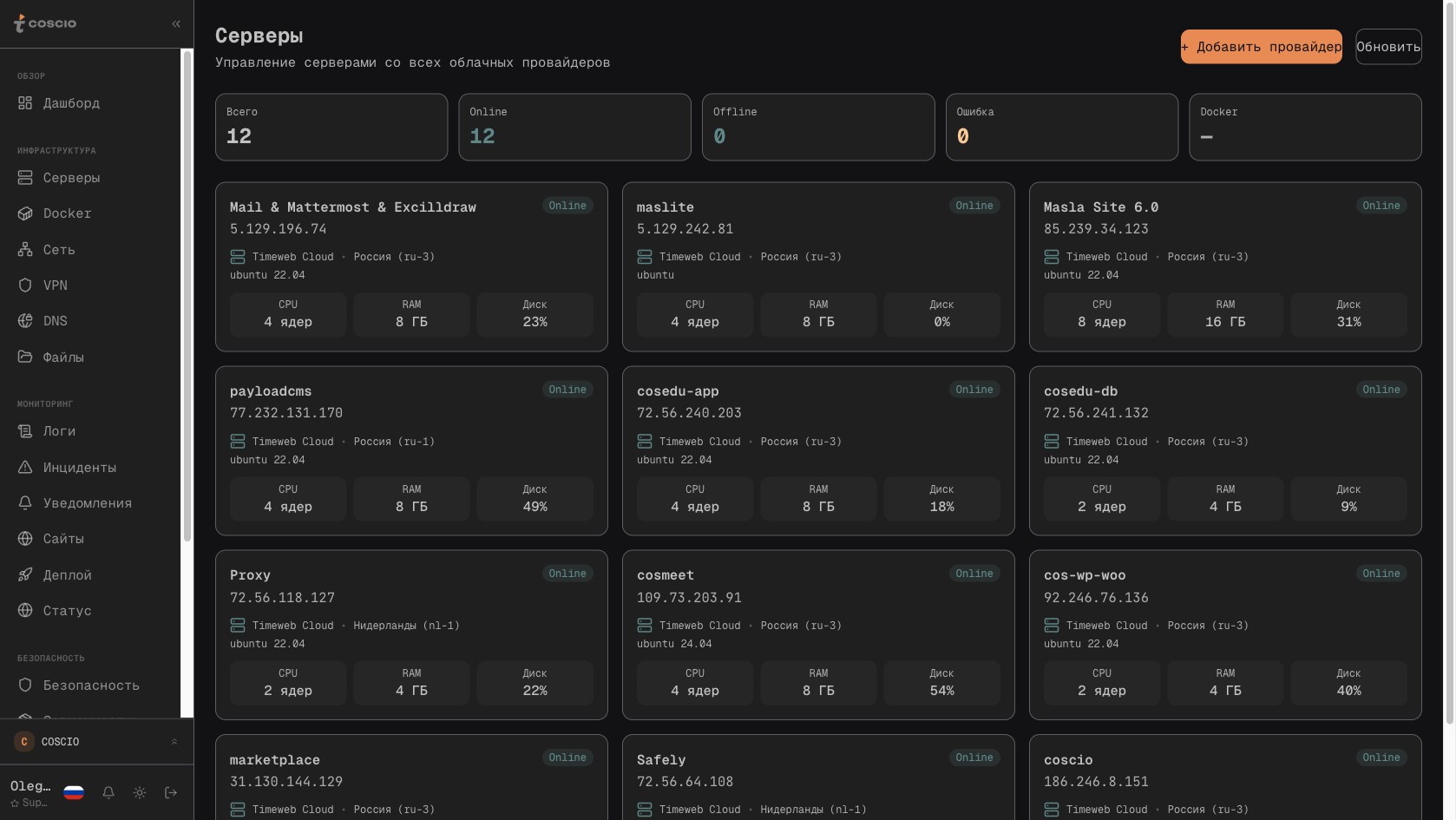
Полный список серверов рабочего пространства — отсюда начинается любая операция, любая диагностика, любое массовое действие
Возвращаясь к посылке, с которой начался этот разговор: парк из десяти-двадцати серверов в нескольких облаках — это не исключительный кейс крупной IT-компании, это типовой профиль среднего бизнеса в 2026 году. Стандартный состав такого парка можно описать почти универсально. Два-три сервера выделены под основное продуктовое приложение — обычно это связка backend + database + frontend, иногда разнесённая по разным машинам ради изоляции отказов, иногда собранная в одну ради простоты. Два-три сервера отведены под контент-инфраструктуру — корпоративный сайт, блог, маркетинговые лендинги, и здесь же часто живёт CMS, через которую редакторы загружают материалы. Один-два сервера отвечают за внутренние коммуникации — почтовый сервер, чат-сервер, видеоконференции, иногда там же стоят инструменты для совместной работы вроде вики или таск-трекера. Один-два сервера выделены под CI/CD и служебные нужды — runner для GitHub Actions или GitLab CI, артефакторий, registry для Docker-образов. Один сервер — VPN, через который сотрудники получают доступ к внутренним ресурсам без открытия их наружу. И часто один-два сервера в зарубежной локации — для обхода блокировок внешних API, для прокси к сервисам, недоступным с российских IP, для хранения резервных копий за пределами одной юрисдикции.
Часто к этому набору добавляются ещё резервные машины — холодные standby для критичных сервисов, на которые в случае аварии можно быстро переключиться. Иногда отдельный сервер выделяется под мониторинг — то есть под тот же Zabbix или Prometheus, которые сами по себе требуют ресурсов и должны жить изолированно от наблюдаемых систем, чтобы в случае проблемы продолжать работать. Иногда возникает необходимость в отдельном сервере под бэкапы — особенно если объёмы данных большие и хранение их в S3 становится дорогим, выгоднее держать собственный сервер с большим диском в недорогой локации.
Если посчитать, выходит как раз около пятнадцати машин — иногда чуть меньше, иногда больше. Это не оптимизированная архитектура, это просто сумма всего того, что нужно бизнесу для повседневной работы. И эта сумма не складывается у одного провайдера, потому что у каждого провайдера свои сильные и слабые стороны: у одного дешевле трафик, у другого лучше связность в нужном регионе, у третьего проще конфигурируется VPN, у четвёртого можно платить рублями без проблем с валютным контролем. Любая попытка консолидировать всё у одного контрагента упирается либо в потерю функциональности, либо в рост издержек, либо в стратегический риск зависимости от одного поставщика. Поэтому реалистичный сценарий — не консолидация, а абстракция: оставить инфраструктуру как есть, но построить над ней слой, который скрывает её неоднородность.
Именно эта посылка определяет архитектурные решения COSCIO, и именно она объясняет, почему интерфейс выглядит так, как выглядит, а не иначе. Список серверов — единый, потому что для человека инфраструктура его компании едина, и неважно, сколько у этой инфраструктуры контрагентов. Метрики собираются по единой схеме и показываются в едином виде, потому что человек, который сравнивает нагрузку двух серверов, не должен в уме переводить значения из одного формата в другой. SSH-доступ организован одинаково для всех машин, потому что для оператора нет разницы, у кого физически стоит сервер, если он этим сервером управляет. Уведомления приходят в единый центр, инциденты регистрируются в едином трекере, отчёты формируются по единым правилам. Многообразие провайдеров остаётся ниже уровня видимости — оно реально присутствует и реально работает, но не выходит на поверхность.
Это и есть архитектура единого окна управления — не маркетинговый слоган и не общая идея, а вполне конкретный набор технических решений, каждое из которых отвечает на конкретный болевой паттерн ежедневной работы IT-директора. CloudProvider-интерфейс отвечает на боль "пятнадцать разных API, всех нужно знать". Двухуровневое хранение метрик отвечает на боль "хочу и оперативную диагностику, и долгосрочную аналитику, но без миллиарда записей в таблице". Строго последовательные SSH-операции отвечают на боль "случайно забанили свой собственный IP на трёх серверах одновременно". Уникальные ключи на каждый сервер отвечают на боль "потеряли ноутбук — пришлось перевыпускать ключи на всём парке". Workspace-изоляция отвечает на боль "две команды смешали свои операции, кто-то нажал не на тот reboot". Каждое из этих решений по отдельности можно было бы реализовать костылями вокруг существующих кабинетов, но в сумме они становятся качественно другим продуктом, который меняет не отдельные действия, а сам способ взаимодействия с собственной инфраструктурой.
Есть ещё один аспект, который редко проговаривается явно, но играет огромную роль в реальной эксплуатации — это вопрос человеческой памяти и сменяемости людей. Любая инфраструктура, размазанная по разным кабинетам и оперируемая через индивидуальные привычки отдельных людей, оказывается неявно завязана на этих конкретных людей. Если администратор Иванов помнит, что сервер базы данных live в кабинете Hetzner под аккаунтом, у которого пароль записан в его личной заметке, и что доступ к серверу почты идёт через SSH с его рабочего ноутбука с ключом, который лежит в его домашней папке, — то увольнение Иванова превращается в катастрофу, исследование которой занимает недели. Сколько серверов он знал, к какой именно учётке какой именно сервер прикреплён, какие ключи у него остались на личных устройствах — всё это превращается в задачу археологии. Единое окно с централизованным хранением credentials и ключей решает эту проблему архитектурно: при увольнении любого сотрудника достаточно отозвать его доступ к COSCIO, и он автоматически теряет доступ ко всему, что было доступно через систему. Никаких рассыпанных по личным заметкам паролей, никаких ключей на личных ноутбуках — всё в одном защищённом контуре, который контролируется централизованно.
Этот же принцип работает и в обратную сторону — при найме нового сотрудника. Если у человека только что появилась учётка администратора, ему не нужно объяснять, где какие кабинеты, какие где логины, кому какие SSH-ключи отправить для прописывания. Достаточно дать ему доступ в нужное рабочее пространство с нужной ролью, и он получает весь спектр операций, который ему положен по роли, без долгого онбординга. Время выхода на полную производительность нового администратора сокращается с двух-трёх недель до пары дней. Для растущей компании, в которой технические команды расширяются регулярно, это даёт измеримый выигрыш в скорости масштабирования.
Стоит упомянуть и аспект, связанный с аудиторскими требованиями. Многие компании, особенно те, кто работает с финансовой или медицинской информацией, обязаны вести журналы доступа к инфраструктуре: кто, когда, с какого IP, какие операции совершал. В разрозненной инфраструктуре сбор этих журналов превращается в отдельную задачу — у каждого провайдера свой формат логов, не все провайдеры вообще логируют все операции, часть действий выполняется напрямую по SSH мимо кабинетов и не попадает ни в какие журналы. В COSCIO любая операция, выполняемая через интерфейс, автоматически попадает в журнал действий с указанием пользователя, времени, целевого ресурса и результата. Этот журнал доступен в разделе настроек и может быть выгружен в любой стандартный формат для предоставления аудиторам. Само существование такого журнала меняет поведение операторов в лучшую сторону — когда человек знает, что его действия записываются, он совершает их более осознанно, реже совершает рискованные операции "на пробу", чаще проверяет себя перед тем, как нажать кнопку, последствия которой необратимы.
Отдельно имеет смысл проговорить вопрос совместимости с уже существующей инфраструктурой мониторинга. У многих компаний к моменту, когда они впервые задумываются о едином окне, уже есть Zabbix, Prometheus, какие-то самописные скрипты, телеграм-бот для алертов. Подход COSCIO здесь не заменительный, а дополняющий — система не пытается вытеснить специализированные инструменты мониторинга в их сильной нише, например, Prometheus с его временными рядами и Grafana с её дашбордами для глубокой аналитики. Она забирает на себя то, что эти инструменты делают плохо или не делают вообще — управление операциями, унификацию интерфейсов разных провайдеров, централизованный реестр серверов и доступов. Метрики, которые собирает Prometheus, могут продолжать собираться Prometheus'ом, и при необходимости их данные подтягиваются в COSCIO через стандартные API. Алерты, которые формирует существующая система, могут продолжать формироваться там же, при этом регистрация инцидентов в едином трекере COSCIO добавляется как дополнительный слой. Эта совместимость снижает порог входа — компании не нужно ломать ничего из того, что уже работает, она просто получает поверх существующего стека новый уровень координации.
Если оглянуться на десять лет назад и сравнить, как выглядела работа администратора в две тысячи шестнадцатом и как она выглядит сейчас, разница не столько в инструментах, сколько в количестве и разнообразии того, чем приходится управлять. Десять лет назад типовой средний бизнес имел один-два сервера, и для них хватало одного SSH-клиента и периодического захода в кабинет провайдера за биллингом. Сегодня типовой средний бизнес имеет пятнадцать серверов в трёх облаках, и при той же численности технической команды эти пятнадцать серверов нужно держать в работоспособном состоянии. Прирост сложности в десять раз — а прирост штата на её обслуживание чаще всего нулевой, потому что бизнес не готов нанимать людей пропорционально росту инфраструктурной сложности. Единственный способ закрыть этот разрыв — повышать производительность каждого инженера через инструментарий, который снимает с него рутину переключения контекста и оставляет только содержательную работу. Именно эту задачу решает единое окно — не "автоматизация всего ради автоматизации", а вполне утилитарное "пятнадцать вкладок становятся одной".