Любая команда инженеров, которая работает с инфраструктурой больше двух-трёх лет, рано или поздно оказывается в положении заложника собственного мониторинга. Сначала всё выглядит безобидно: подняли Zabbix или Prometheus, прикрутили Grafana, настроили десяток дашбордов, договорились о порогах CPU и памяти, повесили вебхуки в чат — и какое-то время этот ландшафт честно отрабатывает свои деньги. Потом серверов становится не пять, а пятнадцать, потом тридцать, потом среди них появляются машины в трёх облаках сразу, плюс пара физических серверов в собственной стойке, плюс мониторить нужно не только железо, но и сайты, и SSL-сертификаты, и здоровье Bitrix24, и очереди в 1С, и контейнеры в Docker. И вот тут аккуратный, заботливо собранный стек превращается в очень странную конструкцию: половина данных живёт в одном месте, половина в другом, между ними нет ни общего поиска, ни общего таймлайна, а дежурный инженер ночью переключается между четырьмя вкладками браузера и пытается понять, связан ли скачок ошибок на сайте с тем, что в три часа ночи кто-то запустил долгое обновление через docker compose.
Симптом, по которому проще всего определить, что мониторинг устарел, парадоксален: формально он всё ещё работает. Метрики собираются, графики рисуются, алерты приходят. Просто решения по этим алертам принимаются всё медленнее, инциденты разбираются всё дольше, а новый сотрудник, попадая в этот зоопарк, тратит две недели только на то, чтобы понять, куда вообще смотреть. IT-директор в какой-то момент ловит себя на ощущении, что мониторинг превратился из инструмента, который экономит время, в инструмент, который требует времени на собственное обслуживание. С этого момента стек официально мёртв, даже если технически он жив.
Дальше речь пойдёт о семи характерных признаках, по которым можно с высокой уверенностью сказать: инфраструктурный мониторинг в компании больше не выполняет свою работу. Признаки разные — какие-то относятся к архитектуре данных, какие-то к процессам, какие-то к поведению самих инженеров, но все они объединены одним: каждый из них появляется незаметно, медленно усиливается и в какой-то момент становится фоном, который никто уже не замечает. Если хотя бы три из семи симптомов знакомы — пора честно признать, что наблюдаемость стала тормозом, а не двигателем.
Прежде чем перейти к разбору признаков, стоит зафиксировать один методологический момент. Под "устаревшим мониторингом" в этой статье понимается не возраст конкретного продукта и не год его релиза — Zabbix, появившийся в 2001 году, в умелых руках может закрывать многие из перечисленных ниже задач, а свежеразвёрнутый Prometheus в неумелых — генерировать ровно тот же ворох симптомов. Устаревший мониторинг — это не про софт, это про сложившийся способ работы. Про то, что данные о состоянии инфраструктуры собираются, но не связываются между собой. Про то, что графики рисуются, но никем не используются. Про то, что алерты доставляются, но игнорируются. Про то, что инциденты разбираются, но опыт от этого разбора нигде не сохраняется. Любая из этих ситуаций — симптом не конкретного продукта, а архитектурного подхода, и менять её приходится тоже на уровне архитектуры, а не очередной заменой одной системы мониторинга на другую с теми же привычками работы.
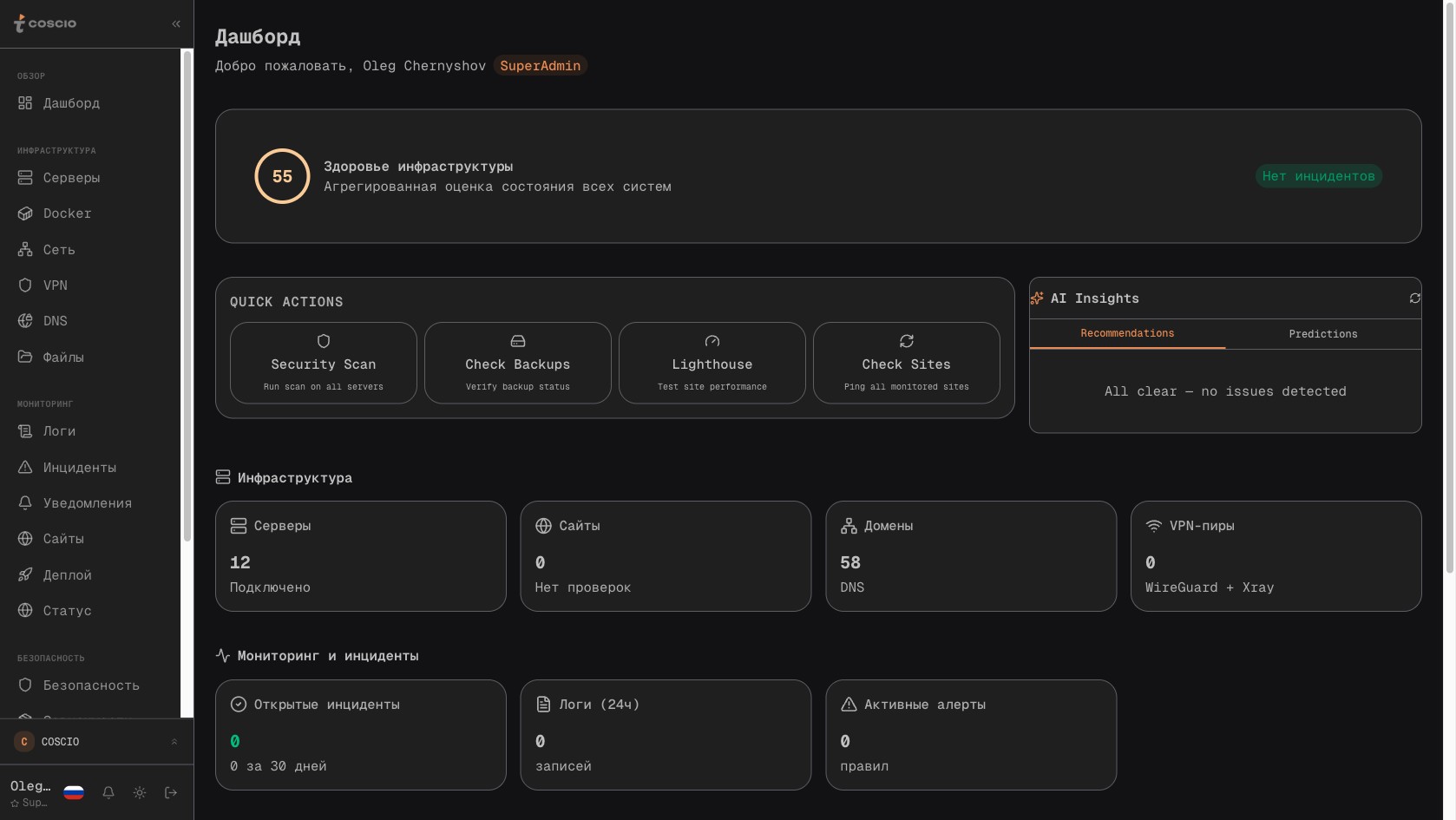
Главный дашборд платформы COSCIO собирает оперативную сводку: серверы, инциденты, SSL, AI-инсайты на одном экране
Признак первый: график есть, действия нет
В классическом мониторинге двадцатилетней давности у графика была единственная функция — показать. Показать, что CPU растёт, что диск заполнен на 87%, что трафик упёрся в потолок канала. Дальше предполагалось, что человек посмотрит на цифры, подумает и пойдёт что-то делать. Это была разумная модель для эпохи, когда у одного администратора было три сервера и он знал каждый из них лично. Сегодня у среднего среднего бизнеса в инфраструктуре десятки виртуалок, и предположение, что инженер будет вручную делать выводы по каждому графику, перестало работать математически.
Симптом устаревания здесь выглядит так: график показал проблему, а дальше инженер должен открыть отдельный SSH-клиент, отдельную панель облачного провайдера, отдельный мессенджер, чтобы согласовать рестарт сервиса, потом отдельный тикетер, чтобы зафиксировать инцидент, потом отдельную систему, чтобы прописать там runbook на будущее. Между графиком и реальным действием — пять-шесть переключений контекста, каждое из которых стоит времени и внимания. В сумме это превращается в десятки минут на инцидент, который технически мог быть разрешён за тридцать секунд автоматического сценария.
В современном понимании мониторинг — это не визуализация, а операционная платформа. Дашборд должен уметь не только показать, но и сделать: рестартануть сервис, выполнить SSH-команду, прогнать smoke-чек, открыть инцидент, оповестить дежурную смену, записать всё это в один таймлайн. Платформа COSCIO построена именно так: страница каждого сервера содержит встроенный xterm-терминал, рядом с метриками лежат кнопки управления питанием, любой алерт автоматически создаёт инцидент, и для типовых ситуаций срабатывает playbook автовосстановления — High CPU гасится через nice/renice, забитый диск чистится по списку известных путей, упавший сервис поднимается через systemctl, истекающий SSL продлевается через certbot, а brute force блокируется правилом fail2ban. Каждое такое срабатывание учитывает cooldown, чтобы не молотить ту же команду в цикле, ограничено лимитом попыток, и подавляется во время запланированного окна обслуживания. Граница между наблюдением и действием исчезает.
Каждый алерт превращается в инцидент с таймлайном, AI-разбором и привязкой к серверу — без переключения между системами
Важное архитектурное следствие из этого подхода: автоматизация действий не отменяет роли человека, она освобождает его время для тех задач, где этого человека невозможно заменить. Когда восемь типовых инцидентов в день закрываются автовосстановлением без участия дежурного, у этого дежурного появляется ресурс на разбор нетипичной аномалии, который раньше откладывался до выходных и зачастую так и не доходил до анализа. Платформа берёт на себя рутину, человек берёт на себя осмысленную работу — именно так должна выглядеть зрелая операционная модель, а не "автоматизация ради автоматизации" и не "пускай человек делает всё, потому что мы боимся доверить машине".
Признак второй: стек собран из четырёх систем, общего поиска нет
Этот симптом проще всего обнаружить простым экспериментом. Команда инженеров получает алерт: сайт компании упал на тридцать секунд. Задача — за пятнадцать минут найти причину. В устаревшем мониторинге это превращается в небольшой квест. Сначала идёт открытие Grafana, чтобы посмотреть метрики хоста, на котором живёт сайт. Параллельно открывается Zabbix, потому что доступность фронтенда мониторит он. Параллельно — кабинет облачного провайдера, чтобы проверить, не было ли сетевых проблем у самого облака. Параллельно — какая-нибудь Kibana или ElasticSearch, чтобы посмотреть логи nginx. Параллельно — отдельная панель мониторинга баз данных, потому что вдруг это медленный запрос. К моменту, когда инженер наконец собирает картину, тридцать секунд недоступности уже превратились в воспоминание, но потратили час рабочего времени и кучу нервов.
Фрагментированный стек — это та самая ситуация, когда каждый отдельный инструмент по-своему хорош, но между ними нет ни общего временного окна, ни единого поиска, ни связной модели данных. Сервер в Grafana и сервер в Zabbix — это два разных сервера для системы, даже если физически это один и тот же хост. SSL-сертификат живёт в одном кабинете, домен — в другом, сам сайт — в третьем. Корреляция событий выполняется в голове дежурного, и качество этой корреляции напрямую зависит от того, насколько он выспался.
Решение этой проблемы лежит не в плоскости интеграций между системами — попытки склеить Grafana, Zabbix и облачные API через дополнительные слои почти всегда заканчиваются ещё одним местом, где данные расходятся. Правильный подход — собрать всё в одну модель данных с самого начала. В COSCIO каждый сервер в инфраструктуре — это объект, к которому привязаны метрики, логи, инциденты, бэкапы, домены, контейнеры, SSL-сертификаты, расходы, плановые окна обслуживания. Дашборд показывает не "графики из Grafana и графики из Zabbix", а единую сущность с её состоянием во времени. Командная палитра по Cmd+K ищет одновременно по серверам, инцидентам, доменам, репозиториям и документам — без необходимости помнить, в каком конкретно кабинете что лежит.
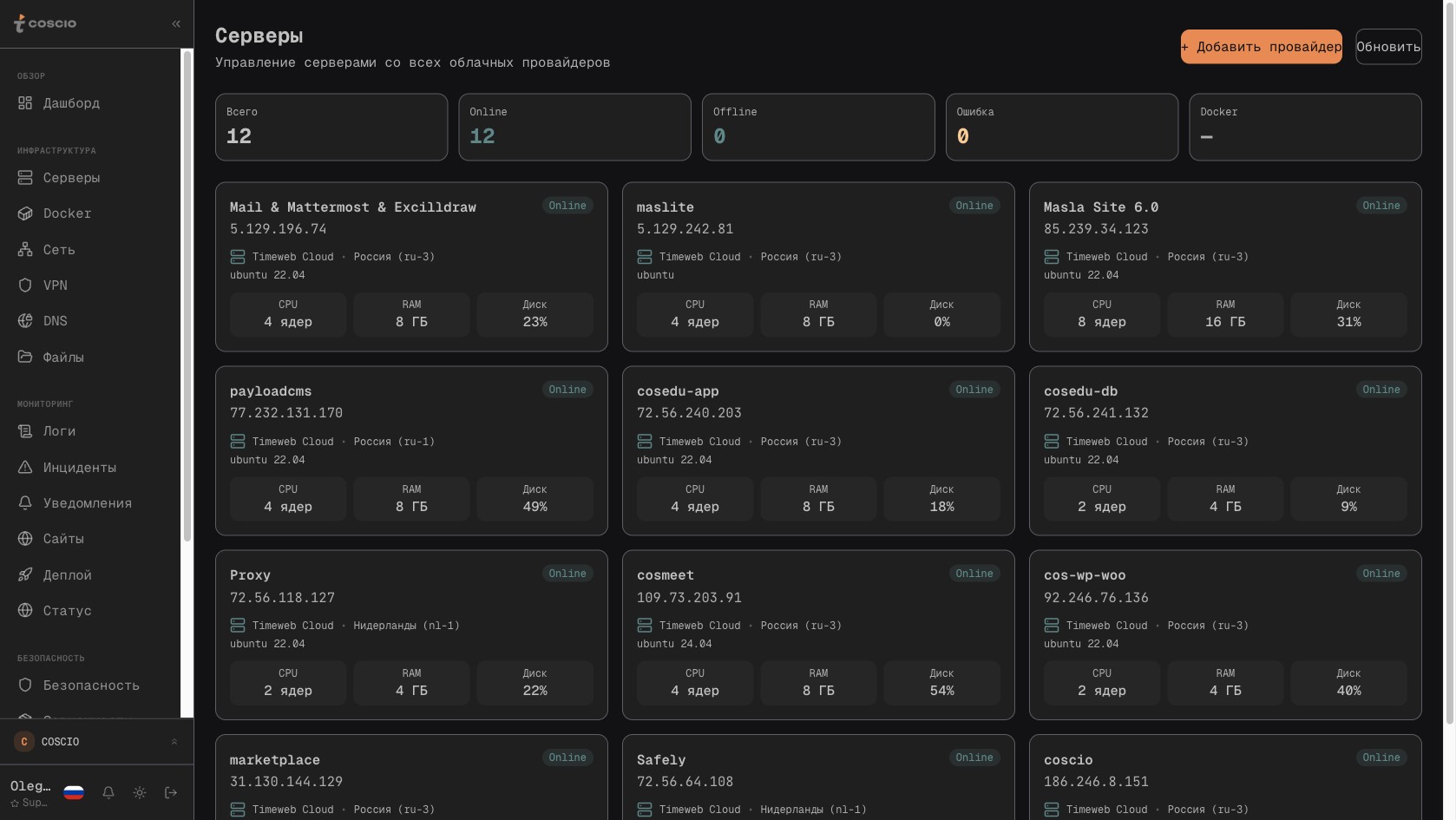
Список серверов из всех подключённых облаков сведён в одну таблицу с актуальными метриками онлайн
Отдельный момент, который редко обсуждают, но который в фрагментированном стеке создаёт неочевидные риски — это разрыв в наименованиях. В одной системе сервер называется по IP-адресу, в другой — по хостнейму, в третьей — по тегу из облака, в четвёртой — по внутреннему идентификатору, который понятен только команде. Когда ночью прилетает алерт от Zabbix с одним именем, а инженер по этому имени ищет хост в кабинете облака с другим именем, и тратит десять минут на сопоставление — это типичный случай. Единая модель данных, в которой каждый сервер имеет один канонический идентификатор, а все возможные алиасы привязаны к нему, снимает этот класс проблем полностью. В COSCIO составной ключ providerId-serverId однозначно идентифицирует машину независимо от того, в каком провайдере она живёт, и все логи, метрики, инциденты, бэкапы по этой машине находятся одним кликом.
Признак третий: графики показывают нагрузку, но не показывают деньги
Это, пожалуй, самый дорогой симптом устаревшего мониторинга, и одновременно самый незаметный. Классическая система наблюдает за тем, что происходит с железом: загрузка процессора, использование памяти, IOPS, сетевой трафик. На что эта нагрузка превращается в счетах от облачного провайдера — за пределами её ответственности. В результате IT-директор видит две параллельные реальности: в мониторинге у него аккуратные графики потребления, а в кабинетах облаков — счета, которые с этими графиками никак не сопоставлены.
Симптомы устаревания здесь следующие: ежемесячный счёт за инфраструктуру стабильно растёт, но никто в команде не может с уверенностью сказать, какой именно сервис, репозиторий или продукт за это отвечает. Расходы на S3-хранение, на исходящий трафик, на дополнительные диски разбросаны по десяткам строк в нескольких разных биллингах, и единственный способ понять, где утечка — посадить аналитика на день и попросить разобрать руками. Когда возникает идея оптимизации — например, перевести часть машин с почасовой оплаты на месячный тариф или перенести тяжёлые задачи с дорогого облака на дешёвое — обоснование делается на интуиции, потому что нет общей картины.
COSCIO выводит финансовые данные на ту же поверхность, что и метрики. Раздел Costs собирает расходы по всем подключённым провайдерам (Timeweb, Hetzner, AWS, DigitalOcean) в единую сущность CostRecord, привязывает их к конкретным серверам, считает прогнозы по тренду, конвертирует в одну валюту по актуальному курсу. AI-инсайт-панель на главном дашборде анализирует структуру затрат и подсвечивает оптимизации: сервер X стабильно загружен на 8% — кандидат на даунгрейд, объём бэкапов Y растёт быстрее данных — стоит проверить retention, исходящий трафик из региона Z вырос втрое — посмотреть, не зашёл ли туда какой-нибудь парсер. Принципиальное отличие: финансовые данные не "тоже доступны где-то рядом", а интегрированы в ту же модель, в которой живут метрики и инциденты, и анализируются тем же AI-движком.
Стоит подчеркнуть и обратный эффект такой интеграции: финансовая прозрачность меняет поведение самой команды. Когда инженер знает, что инфраструктурные расходы по его сервису видны всему руководству и обновляются в реальном времени, он начинает иначе подходить к решениям о масштабировании. Запрос "добавьте мне ещё один большой инстанс" сменяется вопросом "а можно ли уложиться в существующий" — не потому, что так требуют сверху, а потому, что цифры стоят перед глазами. Это тот случай, когда сама по себе визуализация данных становится управленческим инструментом: лишний шаг к согласованию ресурсов отменяется, потому что и так понятно, во что обойдётся каждый вариант.
Признак четвёртый: алерты шумят, потому что система не понимает контекст
Хороший тест на зрелость мониторинга — попросить дежурного инженера показать историю его уведомлений за последние сутки. Если среди них больше двух третей пришлось проигнорировать или отметить как "false positive" — система не выполняет свою главную задачу. Потому что задача алерта не "сообщить, что что-то изменилось", а "сообщить, что нужно действовать". Эти две формулировки кажутся похожими, но разница между ними и определяет, любит инженер свой мониторинг или ненавидит.
Шумный мониторинг возникает по нескольким причинам, и каждая из них — отдельный симптом устаревания. Во-первых, отсутствие окон обслуживания: команда планово рестартует кластер базы данных в воскресенье в четыре утра, мониторинг честно отчитывается о пятиминутной недоступности, и дежурный получает срабатывание, на которое ничего не нужно делать. Во-вторых, отсутствие cooldown: один и тот же диск, заполненный на 95%, генерирует двадцать одинаковых алертов в течение часа, потому что система каждый раз сравнивает текущее значение с порогом и каждый раз заходит выше. В-третьих, отсутствие дедупликации: тот же самый алерт прилетает одновременно в почту, в телеграм и в SMS, и инженер тратит время на то, чтобы убедиться, что все три уведомления — про одно и то же событие. В-четвёртых, отсутствие per-user настроек: рассылка идёт ковровая, по всем 24 типам событий, и через две недели человек привычно сбрасывает уведомления, не читая.
Современная платформа должна понимать контекст. В COSCIO механика подавления шума выстроена на нескольких уровнях. Maintenance Windows — это первоклассная сущность в системе: достаточно один раз указать, что в воскресенье с трёх до пяти утра ведутся работы на сервере X, и за это окно ни один алерт по этому серверу не создаст инцидент и не уйдёт никому в уведомления. У каждого playbook автовосстановления настраивается cooldown в секундах и максимальное число попыток в окне — если за десять минут диск чистился уже три раза, четвёртой попытки не будет, вместо этого создаётся инцидент с уровнем выше для ручного разбора. Уведомления типизированы — 24 категории событий — и каждый пользователь сам выбирает, какие он хочет получать по каким каналам: критичный инцидент по SMS и в Telegram, обычное падение метрики только в in-app SSE-уведомлении в браузере, ежедневный дайджест по почте. Получается, что человек видит ровно ту воронку событий, на которую он подписан, и ровно по тем каналам, которые он сам считает уместными.
Каждый пользователь сам выбирает каналы и типы событий — 24 категории, пять способов доставки, никаких ковровых рассылок
Признак пятый: логи живут в разрозненных хранилищах, корреляция руками
Если про метрики ещё худо-бедно можно сказать, что классические системы их собирают, то с логами в большинстве компаний дело обстоит намного хуже. Серверные логи лежат в journalctl на самих серверах — чтобы посмотреть, нужно зайти по SSH. Логи Docker-контейнеров — отдельно, в docker logs. Логи Bitrix24 — в его собственном кабинете, под учётной записью с правами администратора, доступ к которому есть у двух человек. Логи 1С — где-то внутри OData-эндпоинтов, к которым умеют ходить только специализированные интеграторы. Логи приложений — каждое приложение пишет туда, куда умеет: кто в файл, кто в stderr, кто в свою отдельную таблицу в БД.
Когда нужно расследовать инцидент, дежурный собирает эту мозаику руками. Открывает SSH, делает journalctl, фильтрует по времени. Параллельно открывает Bitrix24 и смотрит, что происходило в CRM в момент инцидента. Параллельно проверяет последние операции в 1С через интеграционный модуль, к которому, скорее всего, придётся писать запрос менеджеру 1С, потому что прямого доступа у дежурного нет. Параллельно перебирает контейнеры на затронутых хостах. Корреляция между этими источниками — упражнение на внимательность и удачу. Если инцидент был сложным, расследование занимает часы, а итоговый разбор полётов оказывается неполным, потому что какие-то источники просто не успели проверить.
В COSCIO принципиально другой подход: единая таблица log_entries в PostgreSQL, в которую пишут все источники по расписанию BullMQ-воркера. Серверные логи через journalctl по SSH — каждые 15 минут. Логи Docker-контейнеров — каждый час. События Bitrix24 — четыре раза в час, на 5, 20, 35 и 50 минуте. Операции 1С — тоже четыре раза в час, со сдвигом на 10, 25, 40, 55, чтобы не сталкиваться с Bitrix-сбором. События самого приложения (старт, остановка, ребут) — мгновенно. Cleanup устаревших записей — раз в сутки, в четыре утра. Поверх этой таблицы — единый поиск с фильтрами по источнику, серверу, категории, уровню логирования и временному окну. Расследование инцидента превращается в один запрос, который захватывает одновременно серверный уровень, контейнерный уровень и бизнес-системы.
Расписания сбора, что важно, не зашиты в код — они хранятся в таблице settings и редактируются суперадмином через интерфейс Settings → Platform → Scheduler. Это означает, что нагрузку на сторонние системы (особенно на Bitrix24, у которого есть лимиты на REST API) можно тонко регулировать без передеплоя: если оказалось, что четыре сбора в час слишком агрессивны для конкретного портала, частота снижается до двух за минуту в интерфейсе, и BullMQ перерегистрирует repeatable job на лету. То же касается retention: глобальная переменная LOG_RETENTION_DAYS (по умолчанию 30) меняется через тот же интерфейс, без необходимости лазить в код или останавливать воркер. Гибкость на уровне настроек делает платформу пригодной к работе и в маленькой команде с тремя серверами, и в крупной инфраструктуре с десятками источников — без изменений в логике.
Единая лента log_entries: serv, docker, Bitrix, 1C, app — фильтры по источнику и временному окну на одной странице
Признак шестой: AI-аналитики нет, оператор всегда реагирует постфактум
Этот симптом обычно маскируется самой постановкой задачи. Если спросить у команды эксплуатации, нужна ли им предиктивная аналитика и AI-разбор инцидентов, типичный ответ — "у нас и без этого нагрузка большая". Это ответ человека, который никогда не работал в стеке, где предсказание реально работает. Потому что фраза "у нас нагрузка большая" в большинстве случаев означает ровно то, что описано в этом признаке: оператор всю смену реагирует на уже случившееся, тушит пожары, разбирает последствия — и у него нет ни одного инструмента, который бы помог ему перехватить инцидент до того, как он стал инцидентом.
В устаревшем мониторинге аналитика — это раздел "Reports", куда дежурный заходит раз в месяц, чтобы сделать скриншот для отчёта руководству. Никакой работы по предсказанию там не ведётся, никаких паттернов из истории инцидентов не извлекается, корреляции между ростом одной метрики и падением другой нужно искать глазами. Если у компании трижды в течение полугода падал сервис из-за того, что забивался определённый раздел диска — об этом помнят два человека, и когда они уволятся, история начнёт повторяться заново. Если у конкретного сервера есть выраженный паттерн "три дня перед инцидентом RAM растёт по экспоненте" — этот паттерн не извлекается автоматически, и каждый следующий раз его приходится открывать заново.
В COSCIO AI-аналитика встроена в платформу на двух уровнях. Первый — AI Insights Panel на главном дашборде: модель (Anthropic Claude основной, OpenAI GPT как fallback) каждую минуту анализирует состояние инфраструктуры и выдаёт топ рекомендаций — открытые инциденты, требующие внимания, провалившиеся бэкапы, SSL-сертификаты со сроком меньше критического порога, критические CVE в Docker-образах, возможности оптимизации затрат. Это не общие советы, а ссылки на конкретные объекты с предложением конкретного действия. Второй уровень — модуль предиктивной аналитики: на исторических данных метрик строится линейный тренд для каждого сервера, и если экстраполяция показывает выход за порог в ближайшие сутки, открывается опережающий инцидент. Параллельно анализируются паттерны из истории инцидентов — какие серверы чаще всего падают по утрам понедельника, какие сервисы стабильно вылетают после деплоя — и эти знания подсвечиваются на этапе планирования работ, а не после очередного факапа.
Принципиально, что AI-движок здесь не является самостоятельной фичей "поверх" мониторинга — он работает на тех же данных, что и весь остальной интерфейс, и использует ту же модель сущностей. Когда модель формирует рекомендацию "сервер X стоит проверить — за последние семь дней он трижды выходил за порог CPU в одно и то же время суток", она ссылается на конкретные инциденты в базе, открываемые одним кликом из карточки рекомендации. Это не "общий совет, который нужно как-то применить", а конкретное действие в конкретном контексте. Тот же AI-движок отвечает за анализ открытого инцидента: при создании каждого нового инцидента вызывается контекст-билдер, который собирает метрики затронутого сервера за нужное окно, релевантные логи, недавние деплои в связанных репозиториях, и передаёт всё это в модель. На выходе дежурный получает не голый алерт "CPU превысил 90%", а структурированный разбор: что именно происходит, какие сервисы потенциально затронуты, какие действия имеет смысл проверить в первую очередь, какие команды могут помочь. Время от срабатывания алерта до начала осмысленных действий сокращается в разы — и это даже без учёта автовосстановления.
AI-аналитика разбирает состояние инфраструктуры и выдаёт конкретные рекомендации со ссылками на объекты
Признак седьмой: знание "как чинить" живёт в головах конкретных инженеров
Это самый коварный симптом, потому что он не выглядит как проблема мониторинга. Скорее, он выглядит как проблема людей. У компании есть Михаил, который один знает, как поднимать упавший кластер баз данных, есть Анна, которая одна понимает, что делать, когда отваливается интеграция с 1С, есть Сергей, без которого не получится восстановить почтовый сервер после сбоя. Каждый из них работает с инфраструктурой годами, знание у них в голове, на бумаге это знание не записано, в системе мониторинга — тем более. Когда дежурит кто-то другой, и случается типовой инцидент, дежурный набирает в три часа ночи Михаила, Михаил спросонья диктует команды, дежурный их вводит, и через час всё работает. Все привыкли, никто не считает это ненормальным.
На самом деле это огромная проблема, и она напрямую относится к зрелости мониторинга. Потому что зрелая платформа наблюдаемости — это не только набор графиков, но и набор знаний о том, что делать при типовых инцидентах. Если у компании случается одна и та же ситуация трижды в год, и каждый раз решение приходит от конкретного человека по телефону, это означает, что система не накапливает институциональную память. Каждый уход сотрудника становится потерей экспертизы. Каждый новый сотрудник проходит через мучительный период вхождения, потому что знания нигде не зафиксированы. Каждое ночное дежурство — лотерея: повезёт-не повезёт дозвониться до нужного человека.
Современная платформа решает эту проблему через playbook'и автовосстановления и привязанные runbook'и. В COSCIO Security-модуль содержит набор готовых playbook'ов на типовые сценарии — High CPU, Disk Full, Service Down, SSL Expiring, Brute Force — каждый из которых описан в декларативной форме: триггер, последовательность действий, cooldown, лимит попыток, поведение во время окна обслуживания. Когда срабатывает соответствующий алерт, playbook отрабатывает автоматически. Если автовосстановление не сработало или сценарий нестандартный — к инциденту прикладывается AI-разбор: модель смотрит на метрики, логи, историю похожих инцидентов и предлагает конкретный план действий. И, что не менее важно, каждый инцидент фиксируется в таймлайне со всеми принятыми решениями — это и есть та самая институциональная память, которая раньше уходила вместе с уволившимся инженером.
Детальная карточка сервера сводит метрики, логи, контейнеры, SSL, окна обслуживания и встроенный терминал на одной странице
Архитектурное замечание: мониторинг 2026 года — это не графики, это платформа
Если попытаться сжать всё сказанное выше в одну формулу, она звучит так: мониторинг перестал быть отдельной системой и стал слоем операционной платформы. Граница между "мы наблюдаем" и "мы управляем" в современной архитектуре отсутствует, и это не случайная мода, а ответ на вполне реальный сдвиг в инфраструктуре. Компания, у которой пятнадцать сервисов размазаны по трём облакам, плюс физика, плюс десяток сторонних SaaS-интеграций, физически не может позволить себе четыре разных интерфейса для наблюдения и пять разных для управления. Слишком много контекста теряется на стыках, слишком дорого обходится каждое переключение между инструментами.
Технически это означает, что в основе должна лежать одна модель данных, одна шина событий, один поиск и один таймлайн. В COSCIO эта идея реализована через PostgreSQL 16 как единое хранилище для всех сущностей — серверов, метрик, инцидентов, логов, бэкапов, SSL-сертификатов, расходов, окон обслуживания, playbook'ов, уведомлений — и BullMQ-воркер как единый исполнитель фоновых задач, расписания которого настраиваются через интерфейс суперадмина (Settings → Platform → Scheduler). 19 очередей, в каждой свой жанр работ, общая логика управления — окна обслуживания, ретраи, dead letter queue. Воркер живёт отдельным процессом под systemd-юнитом, что отделяет нагрузку фонового мониторинга от обработки HTTP-запросов и не позволяет одному сломать другое.
Multi-tenant архитектура — ещё одна вещь, которую устаревший мониторинг практически никогда не умеет. В классическом стеке "одна команда — один Grafana", и если у компании есть несколько проектов, каждый со своей командой, отдельной зоной ответственности и отдельным бюджетом — приходится либо городить копии всего стека (умножая стоимость владения), либо делать вид, что всё это один большой проект, в котором все видят всё. COSCIO с самого начала спроектирована как multi-tenant платформа: один пользователь может состоять в нескольких рабочих пространствах, в каждом — свои серверы, свои интеграции, свои настройки, свои бэкапы, свой биллинг. Переключение между пространствами — одно действие в сайдбаре, под капотом — изменение cookie workspace_id и фильтрация всех запросов по orgId на уровне Prisma.
Прозрачность для внешнего мира — ещё один уровень, который в большинстве устаревших систем отсутствует совсем. Если у клиента или партнёра возникает вопрос "что у вас сейчас работает, что не работает", единственный честный ответ от компании со старым мониторингом — "сейчас посмотрим, перезвоним". Это плохой ответ. Хороший ответ — публичная Status Page, которую внешние пользователи могут открыть в любой момент и сами увидеть, что система здорова, или что есть инцидент, или что идут плановые работы. В COSCIO Public Status Page собирает статус по всем сервисам, привязанным к рабочему пространству, показывает текущие инциденты и окна обслуживания, и обновляется без аутентификации — её можно открыть с любого устройства и поделиться ссылкой со стейкхолдером.
Public Status Page работает без аутентификации и даёт внешнему миру честную картину текущего состояния сервисов
Что остаётся за кадром
В этой статье намеренно не затронуты несколько тем, которые тоже относятся к зрелости мониторинга, но требуют отдельного разговора. Не разобрана глубокая интеграция со SIEM (в COSCIO это Wazuh, отдельная история про корреляцию событий безопасности с инфраструктурными). Не разобран модуль OpenTelemetry-трейсинга, который позволяет видеть распределённые запросы между микросервисами и связывать их с метриками хоста. Не разобран механизм threat-intelligence и brute-force-collector, которые анализируют попытки несанкционированного доступа в реальном времени. Не разобраны интеграции с CI/CD, которые связывают деплой с возникающими после него инцидентами.
Каждая из этих тем — отдельный пласт работы, и попытка уместить их в одну статью превратила бы текст в перечисление. Здесь была другая задача: показать, что зрелый мониторинг 2026 года узнаётся не по списку фич, а по способу мышления. Если в основе лежит одна модель данных, общий таймлайн, интегрированные AI-инсайты, типизированные уведомления с per-user настройками, окна обслуживания как первоклассная сущность, playbook'и автовосстановления и публичный статус для внешнего мира — стек жив. Если каждая из этих вещей — отдельная система, между которыми клиент-серверная переписка и ручные интеграции — стек устарел, даже если каждая отдельная его часть выглядит современно.
IT-директор, который примеряет на свой стек семь признаков из этой статьи и обнаруживает совпадение по пяти из них, оказывается перед типичной развилкой: вкладывать ещё один цикл усилий в дотачивание текущей конструкции — или сделать шаг в сторону платформы, в которой эти задачи решены на уровне архитектуры. У каждого подхода свои аргументы, и однозначно правильного ответа здесь нет. Есть только один вопрос, на который стоит ответить честно: сколько ещё инцидентов команда готова разобрать в ручном режиме, переключаясь между четырьмя вкладками браузера, прежде чем согласиться, что мониторинг — это уже не графики, а операционная платформа.
Важно также понимать, что переход от устаревшего стека к зрелой платформе — это не одномоментное действие, а процесс, который имеет свою экономику. Стоимость владения старым мониторингом редко считают честно: помимо лицензий и серверов под него, в неё входят часы инженеров на ручную корреляцию, на поддержание интеграций между разрозненными системами, на разбор инцидентов по принципу "позвоните Михаилу", на ввод новых сотрудников в курс дела, на расследование инцидентов, причины которых так и остаются неустановленными из-за пропавших логов. Когда эти скрытые расходы аккуратно сводятся в одну таблицу, выясняется, что фрагментированный стек обходится в разы дороже консолидированной платформы — просто эта стоимость размазана по фонду оплаты труда и не видна в графе "расходы на мониторинг". Зрелая платформа, напротив, превращает значительную часть этой невидимой работы в видимую автоматизацию, которую можно посчитать, оптимизировать и оценить.
Ещё один аспект, о котором стоит сказать в заключение — это влияние выбора мониторинга на культуру команды. В компании, где наблюдаемость превратилась в обузу, постепенно складывается определённый стиль работы: инженеры избегают дежурств, разборы инцидентов превращаются в формальность, новые сотрудники долго не задерживаются, потому что не выдерживают информационного шума. И наоборот, в команде, где платформа берёт на себя рутинную работу, освобождает время на содержательные задачи, накапливает знания в форме playbook'ов и позволяет каждому видеть полную картину происходящего — формируется совершенно другая атмосфера: инженерная работа перестаёт быть тушением пожаров и становится тем, чем она должна быть по своей природе — проектированием, улучшением, развитием. И этот сдвиг в культуре оказывается, пожалуй, главным аргументом в пользу того, чтобы признать устаревший мониторинг проблемой и заняться её решением прямо сейчас, не откладывая до следующего крупного факапа, после которого менять что-либо будет уже намного дороже.