Безопасность инфраструктуры — это та область, которая для маленькой компании выглядит как чёрный ящик с надписью «не трогать, пока работает». Сетевой инженер настроил файрволл, сисадмин закрыл root по SSH, разработчик регулярно обновляет npm-пакеты, и вроде бы всё в порядке. Только в какой-то момент в логи прилетает строка about установке xmrig, ssh начинает падать под потоком попыток входа из IP-диапазонов восточной Европы, а в зависимостях фронтенда оказывается пакет, которого там быть не должно. И тогда становится понятно, что отдельные настройки на отдельных серверах — это не безопасность, это её симуляция. Безопасность — это система видимости и реагирования, которая работает 24/7, видит все серверы одновременно, агрегирует события и умеет действовать без человека, пока человек спит.
COSCIO как раз и строит такую систему. Не SIEM в классическом смысле — для этого есть Wazuh, с которым COSCIO интегрируется через webhook, — а более простую и более прагматичную надстройку над парком из десяти-двадцати серверов, которая знает, что на этих серверах слушает порты, какие пакеты установлены, какие версии этих пакетов имеют известные CVE, кто пытался войти ночью и какой плейбук должен сработать, если что-то пошло не так. Это инструмент IT-директора, а не специалиста по информационной безопасности. Но именно для уровня IT-директора такой инструмент сейчас и нужен, потому что специалиста по ИБ в штате обычно нет.
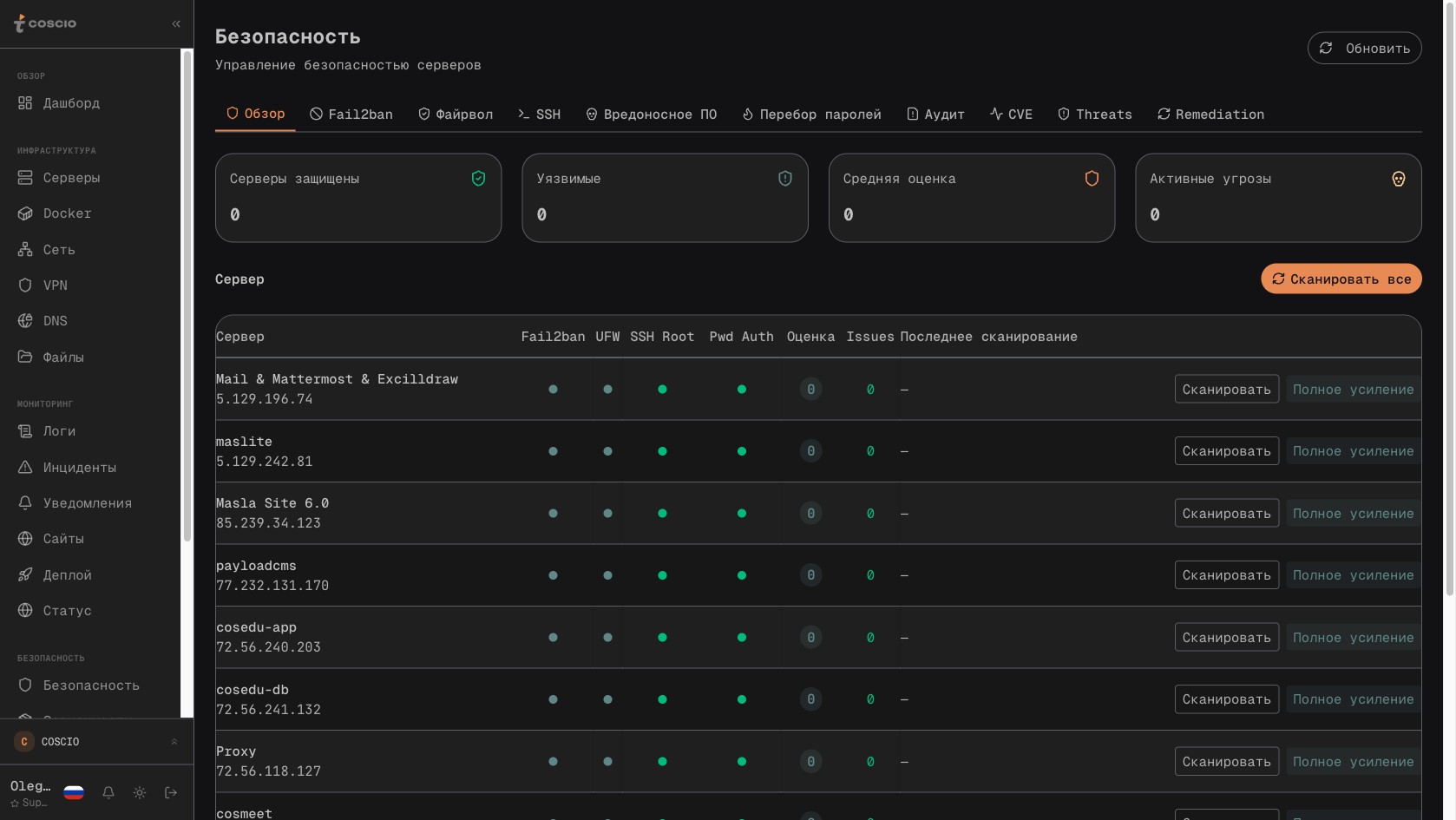
Раздел Security в COSCIO — security score, threats, compliance checks
Чтобы понять, какие задачи безопасности COSCIO решает и как именно, стоит сначала посмотреть на текущий ландшафт угроз для инфраструктуры небольшой компании. Это не история про APT и государственных хакеров — это история про то, что любой VPS с открытым ssh на стандартном порту через несколько минут после подключения к интернету начинает получать первые попытки перебора. Ботнеты сканируют адресные диапазоны облачных провайдеров круглосуточно, и если в auth.log не написано «10 000 failed login attempts from 89.248.x.x», то это означает не что сервер никому не интересен, а что fail2ban работает и автор просто этого не видит. Видимость — первая задача безопасности. Без неё все остальные настройки слепы.
Вторая категория угроз — supply chain атаки в экосистемах пакетных менеджеров. За последние пять лет npm, PyPI и RubyGems столкнулись с десятками случаев, когда популярный пакет с миллионами установок в неделю получал вредоносное обновление — потому что у его мейнтейнера украли учётку или потому что новый «помощник» оказался плохим парнем. event-stream, ua-parser-js, colors.js, ctx — это лишь самые громкие истории. Менее громких — сотни. И ни одна из них не была бы обнаружена обычным сисадмином в обычной компании, если бы кто-то не выложил советующую публикацию на Hacker News. Видимость зависимостей и оперативное реагирование на CVE — вторая задача безопасности.
Третья категория — уязвимости в Docker-образах. Здесь часто возникает иллюзия, что хостовая ОС обновлена, значит, всё безопасно. На самом деле base-image, на котором собран контейнер с приложением, мог быть собран три года назад и содержать в себе устаревший glibc, openssl или Python с известными RCE. Контейнер запускается, приложение работает, и никто не вспоминает, что внутри живёт код, дыры в котором описаны на NVD ещё в 2022 году. CVE-сканирование образов — отдельная задача, которую host-сканер не закрывает.
Четвёртая категория — эксплойты процессов с избыточными привилегиями. Свежий пример из практики индустрии — Monero-майнер xmrig, установленный через скомпрометированный root-процесс под PM2. Схема банальная: разработчик запустил pm2 startup от root, чтобы node-приложения переживали ребут, в одной из node-зависимостей оказалась RCE, RCE сработала под uid 0, и через несколько часов в /tmp лежал бинарь криптомайнера, оформленный как systemd-сервис под видом обновления ядра. Это всё разворачивается за минуты, обнаруживается через сутки по аномально высокой нагрузке на CPU, и единственная причина, по которой такое возможно, — выбор «удобства» в виде root над «безопасностью» в виде непривилегированного юзера и systemd с NoNewPrivileges, ProtectSystem=strict и пустым CapabilityBoundingSet. Compliance-проверки конфигурации сервисов — пятая задача безопасности.
Эти пять категорий и формируют структуру раздела Security в COSCIO. Не как набор галочек в чек-листе, а как пять независимых, но связанных через инциденты подсистем. Если упрощённо: dependency scanner отвечает за пакеты и образы, port auditor — за сетевую поверхность, brute-force collector — за поведение на ssh-уровне, auto-remediation — за реагирование, compliance checks — за состояние конфигов. Поверх них лежит security score — агрегированная оценка от 0 до 100, которая считается на основании результатов всех пяти подсистем по каждому серверу.
Сегментация задач безопасности на эти пять независимых блоков — намеренная архитектурная декомпозиция, которая повторяет реальную сегментацию работы команды безопасности в крупных компаниях. Там этим занимаются разные люди, потому что у каждой задачи свои источники данных, своя периодичность, свои инструменты и своя модель угроз. В COSCIO эти подсистемы делают разные крон-задачи в BullMQ, пишут в разные таблицы PostgreSQL, отображаются в разных вкладках интерфейса и могут включаться-отключаться независимо. Но финальный security score и финальный список инцидентов — общие.
Dependency Scanner — первый блок, и для современной компании, в которой большая часть приложений написана на node.js или python, — самый важный. Стандартный npm audit, который запускается локально на машине разработчика, недостаточен по нескольким причинам. Во-первых, он показывает уязвимости в lock-файле репозитория, а не в реально установленных node_modules на проде. Между «зафиксированной версией» и «развёрнутой версией» может быть пропасть, если деплой произошёл с npm install --legacy-peer-deps или с другим тегом. Во-вторых, npm audit запускается по требованию, а не по расписанию, и его результаты живут в терминале того, кто запустил. В-третьих, в парке из двадцати серверов с разными проектами никто не помнит, на каком сервере какой проект и какие у него зависимости.
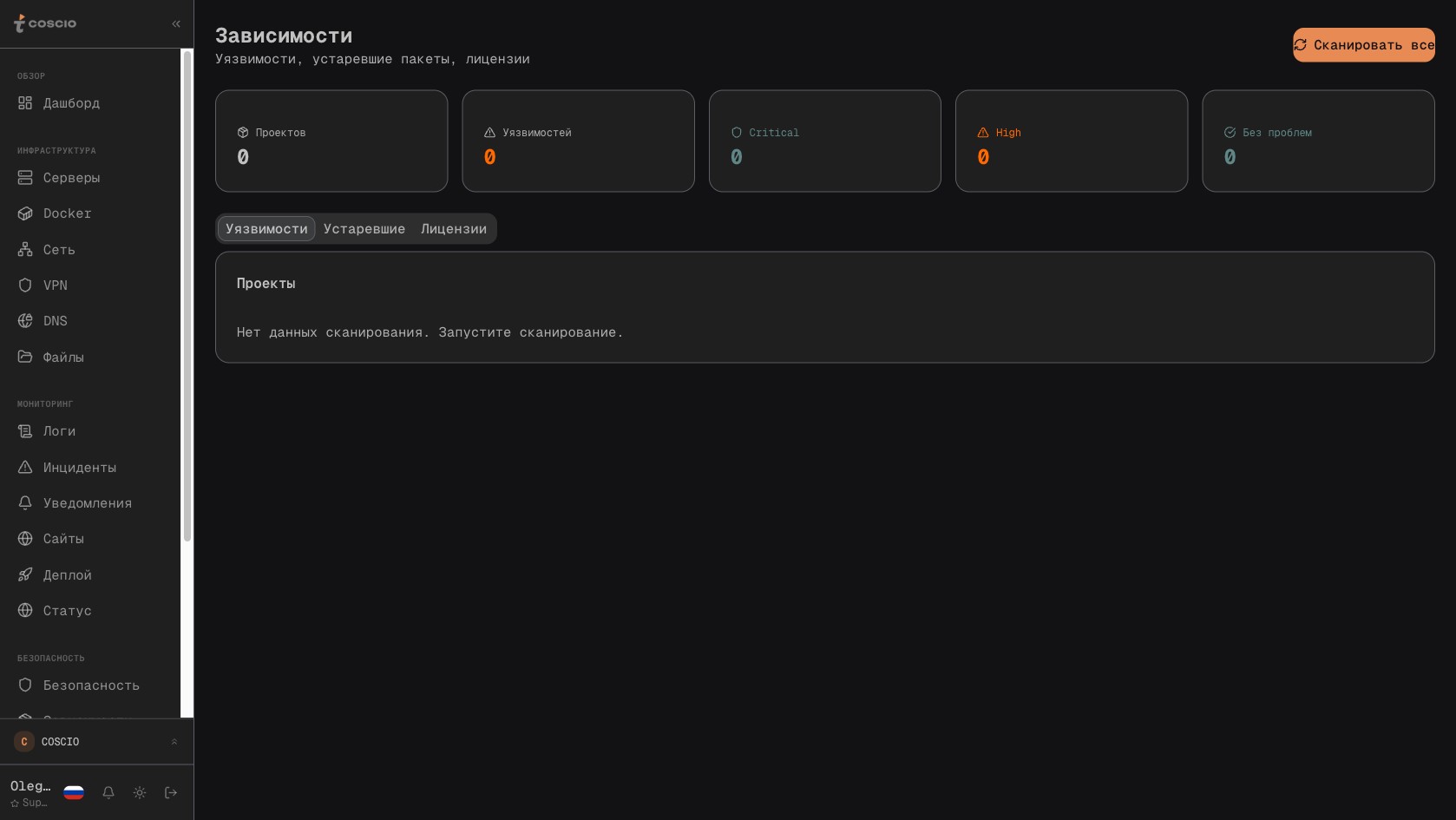
Dependency Scanner в COSCIO — все CVE по всем серверам в одной таблице
В COSCIO Dependency Scanner работает иначе. Он подключается по SSH к каждому серверу в инфраструктуре, обнаруживает все директории с package.json, requirements.txt, Pipfile.lock, composer.json и запускает соответствующий аудит на месте. Результаты — список CVE с severity, описанием, рекомендованной версией и ссылкой на NVD — отправляются в центральную базу COSCIO и агрегируются в одну таблицу. На этой таблице видно: вот сервер cos-payloadcms, на нём проект cosinn-cms, у него 3 critical, 7 high и 24 moderate CVE; вот сервер cos-marketplace, на нём 1 critical и всё; вот сервер cos-vpn, у него вообще нет node-проектов, поэтому строки нет. Один взгляд — общая картина по всему парку.
Ранжирование по severity — отдельная история. CVSS-оценка от 9.0 и выше попадает в critical, от 7.0 до 8.9 — в high, и так далее. Но severity не означает приоритет в реальности. Critical CVE в dev-зависимости, которая используется только при сборке проекта на CI и не попадает в production-бандл, на практике безопаснее, чем moderate CVE в библиотеке для парсинга JSON в API. COSCIO учитывает это через дополнительное поле «контекст использования»: dev/prod/transitive. Critical в dev — оранжевая, critical в prod — красная, critical в transitive (то есть в зависимости зависимости, до которой проект напрямую не обращается) — жёлтая. Это позволяет команде из двух человек не тонуть в водопаде из «обновите всё немедленно», а действовать осмысленно.
SBoM — software bill of materials — генерируется по результатам сканирования автоматически. Это машиночитаемый список всех установленных пакетов с версиями и контрольными суммами, который требуется для compliance с современными стандартами (SLSA, CycloneDX). Для большинства компаний SBoM пока не обязателен, но появляется в требованиях крупных корпоративных клиентов, и иметь возможность экспортировать его одной кнопкой из COSCIO — это часть инфраструктурной готовности к таким требованиям.
Отдельная подзадача — CVE в Docker-образах. Здесь подход немного другой, потому что у Docker-образа нет package.json в привычном смысле. Сканирование идёт через анализ слоёв образа: какие пакеты установлены через apt/yum/apk, какие версии, какие из них содержат известные CVE. Технически это похоже на работу trivy или grype, и в COSCIO под капотом используется именно похожая логика. Регулярная задача в BullMQ обходит все запущенные контейнеры на всех серверах через SSH+docker ps, для каждого контейнера определяет image, и если этот image ещё не сканировался или сканировался более 24 часов назад — запускает сканирование. Результаты складываются в ту же таблицу dependency-результатов, но с типом «container_image» вместо «node_package».
Почему именно образы критичны — стоит сказать отдельно. Когда команда обновляет приложение, она обычно обновляет код приложения и иногда — base-image, на котором оно крутится. Если base-image задан как node:18-alpine без указания конкретного тега вроде node:18.19.1-alpine3.19, то при docker build образ может оказаться разным — иногда новее, иногда старее, иногда вообще из неожиданного зеркала, если кто-то изменил DNS на CI. Закрепление версий base-images и регулярное сканирование на свежие CVE — единственный способ держать эту поверхность под контролем. COSCIO не закрепляет версии за разработчика — это его работа, но видимость того, что в проде сейчас крутится контейнер с устаревшим OpenSSL, COSCIO даёт.
Второй блок Security в COSCIO — аудит открытых портов. Идея простая: на каждом сервере должен слушать ровно тот набор портов, который определён политикой. Веб-сервер — 80, 443, ssh — 22 (или нестандартный). База данных — 5432 на localhost. Метрики — 9090 на localhost. Если на сервере вдруг появился новый слушающий порт, который не входит в whitelist, — это либо легитимное изменение (которое должно быть согласовано и попасть в whitelist), либо аномалия, требующая внимания. COSCIO сканирует через SSH командами вроде ss -tlnp каждые несколько минут и сравнивает результат с эталоном.
Эталон, в свою очередь, не задаётся вручную через UI — это утомительно. COSCIO применяет двухфазный подход: сначала «обучение» в течение нескольких дней, в течение которого формируется естественный профиль портов сервера, потом — «защита», когда любое отклонение от профиля считается событием для расследования. Если за неделю обучения порты сервера cos-payloadcms были 22, 80, 443, 3100 и 5432, то появление на нём порта 4444 — повод немедленно зайти и посмотреть, что это. Часто это окажется legitimate — кто-то поднял временный сервис для теста. Но иногда — нет. В случае с xmrig, кстати, появление слушающего порта для стратум-протокола майнинга было бы одним из первых видимых сигналов компрометации.
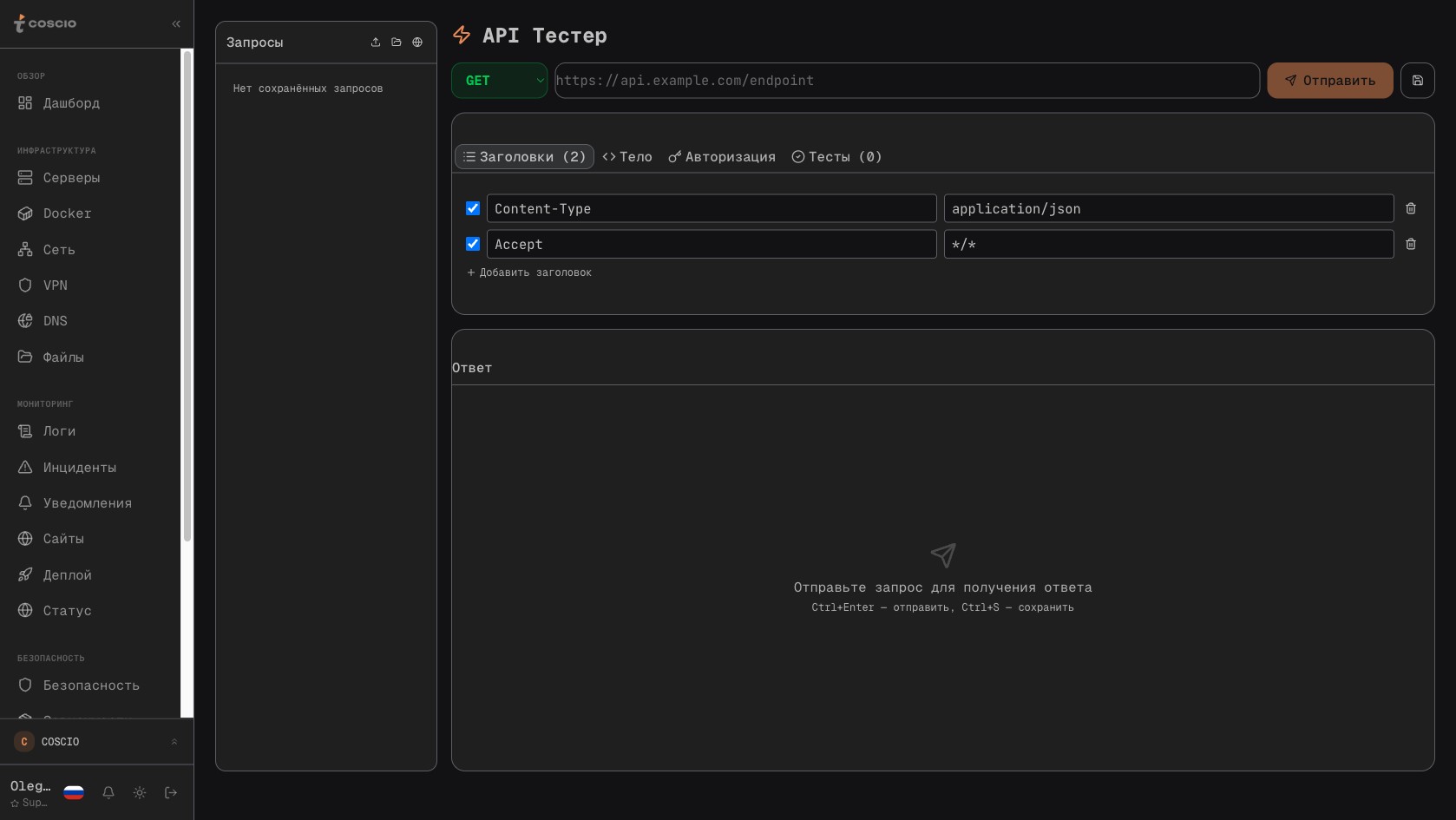
API Tester внутри COSCIO — конструктор запросов, коллекции, переменные окружения
Здесь стоит ненадолго отвлечься на API Tester, который тоже относится к security-инструментам, хотя обычно про него думают как про инструмент разработки. Конструктор HTTP-запросов с коллекциями, переменными окружения, историей вызовов и поддержкой Bearer-токенов и Basic-auth — это, по сути, замена Postman, встроенная прямо в портал. Зачем она в контексте security? Затем, что при расследовании инцидента нужно быстро проверить endpoint: вернётся ли 401 при отсутствии токена, корректно ли работает rate-limit, не отвечает ли admin-API без аутентификации из-за криво написанного middleware. Раньше это требовало переключения в Postman, копирования cookies, ручного оформления запроса. Теперь — одна вкладка в том же портале, где открыт инцидент и где видны логи сервера.
Третий блок — brute-force collector. Это, пожалуй, самая интересная часть Security в COSCIO с точки зрения инженерного решения. Стандартный подход — поставить fail2ban, который читает auth.log и блокирует IP после нескольких неудачных попыток. fail2ban работает и решает свою задачу — блокирует. Но он не даёт картины. Он не отвечает на вопросы: «Сколько уникальных IP пытались зайти за последние 24 часа? По каким аккаунтам? Из каких стран? Растёт ли активность? Есть ли паттерн целевой атаки на конкретный аккаунт, а не общее фоновое сканирование?» Эти вопросы важны, потому что разница между фоновым шумом и целевой атакой огромна. Фоновый шум — это норма, его игнорируют. Целевая атака — это сигнал, что кто-то конкретно интересуется этой инфраструктурой, и надо проверить, не утекли ли где-то учётки.
Brute-force collector в COSCIO — это парсер логов и агрегатор. Он подключается по SSH к каждому серверу с включённым ssh (то есть ко всем), читает /var/log/auth.log и /var/log/secure (в зависимости от дистрибутива), парсит строки вида «Failed password for invalid user admin from 89.248.x.x port 33421» и складывает агрегаты в свою таблицу. Агрегаты бывают разные: по IP за час, по аккаунту за день, по стране (через GeoIP), по сочетанию IP+аккаунт. На дашборде видно: за последние 24 часа было 47 213 неудачных попыток с 1 832 уникальных IP, из них 1 654 — на несуществующих пользователей (root, admin, ubuntu, test), 178 — на реальных пользователей. Вот этот второй ряд — 178 попыток на реальных — повод поднять бровь. Особенно если все 178 — на один и тот же логин и с группы IP из одной AS.
Совместная работа с fail2ban здесь устроена так. fail2ban блокирует — это его роль. COSCIO видит. Если fail2ban не установлен — а в hardened-конфигурации с key+TOTP он не нужен и даже вреден, потому что иногда банит собственный IP при перепаритии, — то COSCIO всё равно видит попытки, просто не блокирует их. Видимость без блокировки — это нормальное состояние для сервера, в который нельзя зайти по паролю в принципе. Брут-форс по ssh с password-only аутентификацией бессмыслен, если пароль выключен; он создаёт шум в логах, но не угрозу. Видеть этот шум всё равно полезно — иногда из него выскакивает аномалия. Скажем, попытка входа от существующего пользователя cos с правильным timing-паттерном — это уже не шум, это попытка с какими-то предположениями о структуре системы.
Четвёртый блок — auto-remediation. Это движок, который превращает алерты в действия. Архитектурно это связка «правило → playbook → действие → проверка результата → запись инцидента». Правило формулируется на языке метрик: например, «CPU > 90% за последние 10 минут на серверах с тегом production». Если правило срабатывает — выбирается соответствующий playbook. Playbook — это последовательность SSH-команд с условиями и таймаутами. Например, для «high CPU» builtin-playbook делает следующее: получает топ-5 процессов по CPU через ps aux --sort=-%cpu | head, проверяет, попадает ли первый процесс в whitelist «не трогать» (например, postgres или nginx), и если не попадает — отправляет ему SIGTERM, ждёт 30 секунд, если процесс не завершился — SIGKILL. После — повторная проверка метрик через минуту: если CPU вернулся в норму, инцидент закрывается; если нет — эскалация на следующий уровень (уведомление в Telegram, создание тикета, открытие подробного инцидента в разделе Incidents).
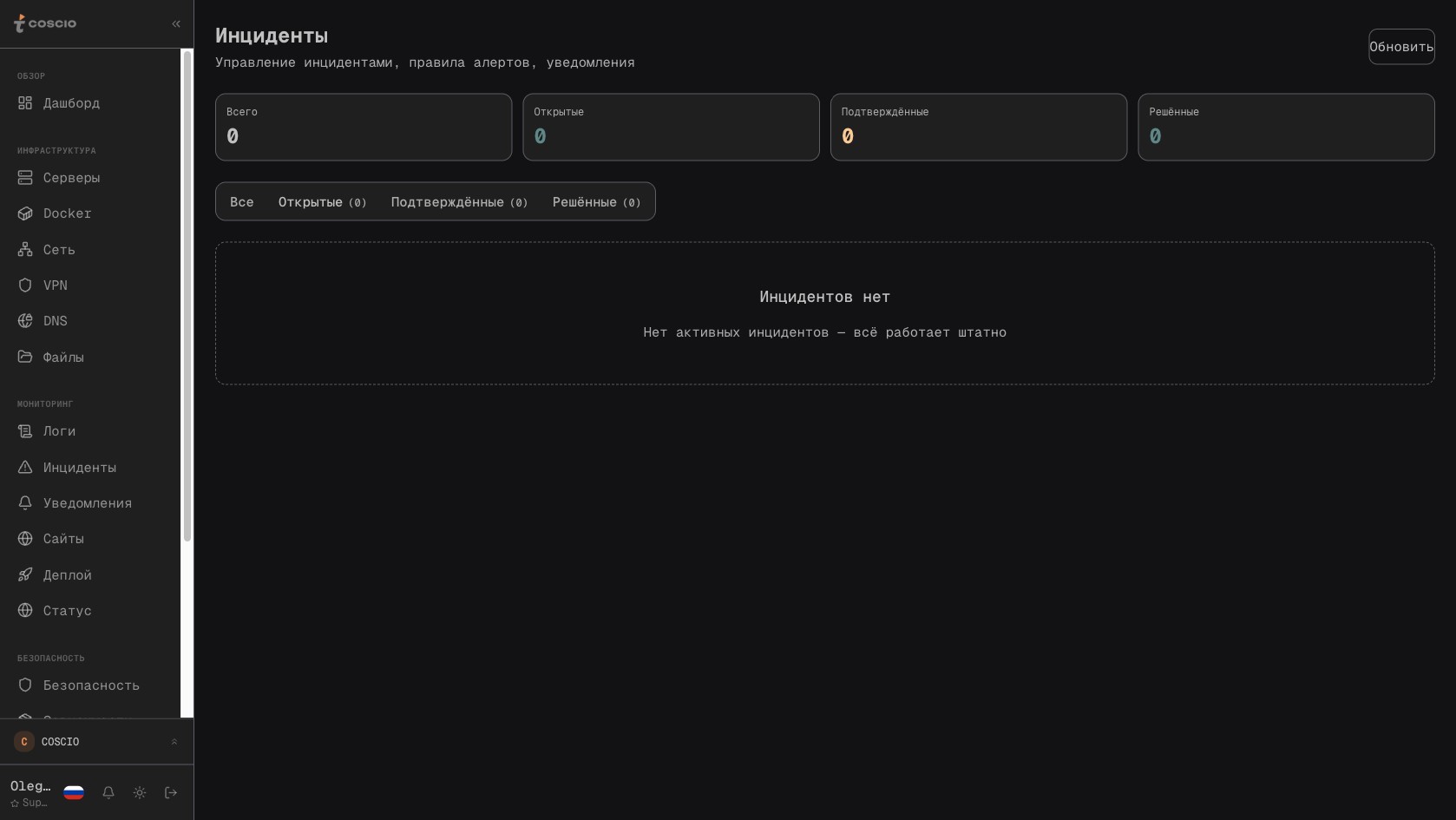
Раздел Incidents — журнал всех инцидентов с привязкой к серверам и playbook'ам
Пять builtin-playbook'ов покрывают самые частые инциденты. High CPU — описан выше. Disk Full — проверка использования диска, очистка журналов journald старше 7 дней, очистка docker-кэша через docker system prune --volumes, повторная проверка. Service Down — попытка systemctl restart сервиса, если он управляется systemd, или соответствующий аналог для PM2-приложений, проверка состояния через minute. SSL Expiring — за 30 дней до истечения сертификата автоматически дёргается certbot renew, при ошибке — алерт в инциденты. Brute Force — при обнаружении агрессивного брут-форса с одного IP добавление этого IP в nftables drop-set на 24 часа (с уведомлением, что блокировка временная, чтобы операторы случайно не забыли про неё навсегда).
Параметры cooldown, max retries и backoff — критически важная часть. Cooldown 5 минут означает, что один и тот же playbook на одном и том же сервере не запустится чаще раза в 5 минут — даже если правило продолжает срабатывать. Это защищает от ситуации, когда алерт срабатывает каждую минуту, playbook стреляет каждую минуту, и сервер уходит в каскад перезапусков. Max retries 3 означает, что после трёх неудачных попыток playbook больше не запускается и инцидент эскалируется к человеку. Backoff exponential — пауза между попытками удваивается: 1 минута, 2 минуты, 4 минуты. Эти параметры настраиваются на уровне правила и могут быть переопределены для конкретного сервера.
MaintenanceWindow — связанная концепция. Это окно, в течение которого auto-remediation на конкретном сервере подавляется. Зачем нужно: представьте, что во время деплоя приложения сервис перезапускается, и в этот момент срабатывает правило «service down». Auto-remediation, не зная про деплой, попытается «починить» сервис, что в лучшем случае добавит шума в логи, а в худшем — войдёт в конфликт с самим деплоем. MaintenanceWindow закрывает эту проблему: оператор объявляет окно с 14:00 до 15:00 на сервере cos-coscio, в течение этого окна все алерты по сервису продолжают писаться в журнал, но действий auto-remediation не выполняет. После окна — действия возобновляются.
Пятый блок — compliance checks. Это набор автоматических проверок конфигураций серверов на соответствие лучшим практикам. Список проверок построен на основе CIS Benchmarks для соответствующих ОС, но адаптирован под реальность маленькой инфраструктуры. Проверяется примерно тридцать параметров на каждом сервере: PermitRootLogin no, PasswordAuthentication no, PubkeyAuthentication yes, наличие AuthenticationMethods publickey,keyboard-interactive, UFW/nftables status, наличие ограничения на cipher suites в SSH, время сессии, MaxStartups, MaxAuthTries, наличие fail2ban (если он используется политикой), отсутствие dangerous-пакетов вроде telnet-server, права на /etc/shadow и /etc/ssh/sshd_config, наличие systemd-юнитов с opasnыми параметрами (User=root + ExecStart= с записываемым путём), и так далее.
Каждая проверка возвращает один из трёх результатов: pass, fail, warn. Pass — параметр соответствует политике. Fail — не соответствует, и это критично (например, PermitRootLogin yes на production-сервере). Warn — не соответствует, но не критично (например, MaxAuthTries 6 при политике 3 — формально хуже, но эксплуатировать сложно). На основании результатов проверок считается часть security score сервера. Полный аудит всех тридцати проверок занимает несколько секунд через SSH и запускается раз в час по умолчанию (настраивается в /settings/platform).
Здесь стоит вернуться к истории с PM2 под root и xmrig, потому что compliance checks именно для таких случаев и нужны. После того инцидента в индустрии в COSCIO была добавлена отдельная проверка: «systemd-юниты, запускающие node-приложения от root, без NoNewPrivileges=yes». Если такой юнит обнаружен — fail с подробным объяснением, почему это плохо: каждая RCE в любой node-зависимости получает root, может писать в /tmp и /var, может создавать systemd-юниты для собственной персистентности, может скачивать и запускать бинари. Альтернатива — запуск под непривилегированным юзером (deploy/app/coscio), с systemd-параметрами NoNewPrivileges=yes, ProtectSystem=strict, ProtectHome=yes, PrivateTmp=yes, CapabilityBoundingSet=, RestrictAddressFamilies=AF_INET AF_INET6 AF_UNIX. Каждый из этих параметров отрезает один из векторов эскалации; вместе они делают невозможной типичную цепочку «RCE → запись бинаря → systemd-юнит → персистентность».
Дашборд COSCIO — security score сразу на главной
Security score — финальная агрегация всех пяти блоков в одно число от 0 до 100. Считается отдельно для каждого сервера и потом усредняется (с весами) для общего score всей инфраструктуры. Вес блоков примерно такой: dependency CVE — 30%, compliance — 30%, port audit — 15%, brute-force trends — 15%, наличие активных инцидентов — 10%. Конкретные веса настраиваются в /settings/platform, по умолчанию они подобраны эмпирически — критические CVE и неправильные compliance-настройки опаснее, чем фоновый брут-форс. Score выше 90 — зелёная зона, 70-90 — жёлтая, ниже 70 — красная. Цель оператора — держать score выше 85 для production-серверов, что технически достижимо при минимальной дисциплине обновлений и грамотных дефолтах настройки.
Интеграция с Wazuh SIEM — отдельная история, появившаяся в COSCIO в мае 2026 года. Для маленьких компаний пять блоков, описанных выше, обычно достаточны. Но есть категория клиентов — финансы, медицина, госструктуры — которым по требованиям регуляторов нужен полноценный SIEM с File Integrity Monitoring, Rootcheck, log analysis по сложным правилам, SCA (Security Configuration Assessment), CIS-audit и так далее. Поднимать полный SIEM на своей стороне COSCIO не пытается — это не его задача. Вместо этого предоставляется webhook-endpoint, на который Wazuh manager отправляет алерты, и эти алерты автоматически становятся инцидентами в разделе Incidents COSCIO.
Технически интеграция устроена так. На стороне Wazuh настраивается active-response с custom hook'ом, который при срабатывании правила выше определённого severity (по умолчанию 7) отправляет POST на адрес COSCIO с подписанным payload'ом. На стороне COSCIO в Prisma моделях есть таблицы WazuhSource, WazuhAlert, WazuhRule, в которые этот payload разбирается. Каждый алерт автоматически создаёт инцидент в общем потоке, с тегом «wazuh» и ссылкой на исходное правило, что делает поиск удобным. Дальше — обычный workflow: оператор смотрит инцидент, принимает решение, при необходимости запускает playbook (если правило подходящее) или закрывает руками.
Сильная сторона такого подхода — Wazuh видит то, чего COSCIO не видит. FIM ловит модификацию /etc/passwd или /usr/bin/sshd, Rootcheck находит rootkit-подобные артефакты, log analysis применяет тысячи готовых правил для разных приложений. COSCIO в свою очередь даёт удобный фронтенд для реагирования и объединяет события Wazuh с собственными данными (метрики, dependency-CVE, brute-force trends) в одной картине. Получается не «или-или», а «и-и»: для команд без Wazuh достаточно встроенных инструментов, для команд с Wazuh — добавляется глубокий слой видимости, не дублирующий, а дополняющий.
Возвращаясь к практическим последствиям — что всё это даёт IT-директору в реальности. Во-первых, видимость. Открыл портал утром, посмотрел security score — если зелёный, можно заниматься другими делами. Если жёлтый — посмотрел, что именно ухудшилось: новые CVE в зависимостях после автоматического сканирования, появился новый слушающий порт, изменилось соотношение брут-форса в сторону целевой атаки. Минута взгляда заменяет полчаса ручных проверок по серверам. Во-вторых, реакция. Алерты не висят в почте, ожидая, пока кто-то откроет ноутбук. Builtin-playbook'и закрывают типовые инциденты в течение минут от срабатывания. Эскалация на человека происходит только тогда, когда автоматика не справилась — это нормальная пропорция.
В-третьих, документирование. Каждый инцидент, каждый запуск playbook'а, каждое срабатывание правила — попадает в базу с timestamp'ом, контекстом и исходом. Когда через полгода нужно отчитаться перед руководством или клиентом, что в инфраструктуре произошло за квартал, ответ есть в готовом виде: 1247 инцидентов, 1183 закрыты автоматически, 64 потребовали вмешательства человека, среднее время реакции — 4 минуты, среднее время до полного закрытия — 23 минуты. Без портала такая статистика собирается за неделю работы по логам и почте, и обычно так и не собирается.
В-четвёртых, compliance. Если в компанию приходит аудит — внешний или внутренний — у IT-директора есть готовый отчёт по compliance-проверкам всех серверов на нужную дату с историей изменений. Не нужно бегать по серверам и проверять, был ли везде PermitRootLogin no в момент, когда поставщик это требовал. Ответ — да, был, вот лог. И SBoM по всем production-приложениям тоже выгружается за минуту, что закрывает требования части корпоративных клиентов и регуляторов.
В-пятых — и это, возможно, главное — снижение зависимости от конкретного человека. Когда сисадмин в отпуске, портал продолжает работать. Если ему когда-то понадобится передать дела — преемник видит ту же картину, что видел предшественник, без необходимости перечитывать чужие конспекты в Notion. Безопасность из «состояния головы одного человека» превращается в состояние системы, которое можно показать, измерить и поддерживать командой.
Если попытаться сформулировать главную идею раздела Security в COSCIO одной фразой, она прозвучит примерно так: безопасность маленькой инфраструктуры не должна требовать выделенного специалиста по информационной безопасности. Должны быть нормальные дефолты, видимость по всем серверам в одном окне, автоматизация для типовых сценариев и возможность подключить внешний SIEM для команд, которым он нужен по регуляторике. Все остальное — конкретные CVE, конкретные правила, конкретные playbook'и — настраивается, эволюционирует и накапливается со временем. Главное — чтобы каркас, на котором всё это держится, был построен один раз и работал дальше без ежедневного внимания.
Стоит подробнее остановиться на одном частном, но важном вопросе — TOTP-секреты и почему в hardened-конфигурации COSCIO у каждого сервера он свой, а не общий. На первый взгляд это создаёт лишние неудобства: вместо одного приложения-аутентификатора с одним секретом приходится держать на телефоне десяток разных записей с уникальными QR-кодами для каждого сервера. На практике это решение защищает от компрометации мобильного устройства как от единой точки отказа. Если у оператора украдут телефон и злоумышленник получит доступ к Google Authenticator, общий секрет даст вход на все серверы инфраструктуры сразу. Уникальный — даст вход на один сервер, и то только при наличии соответствующего приватного SSH-ключа, который хранится отдельно в зашифрованной папке на ноутбуке и тоже свой на каждый сервер. Эта избыточная сегментация — то самое «defense in depth», которое в теории информационной безопасности упоминают на каждой второй странице учебника, а на практике почти никто не применяет, потому что «неудобно». COSCIO в этой части не помогает (TOTP-секреты живут отдельно от портала), но compliance-проверка «общий секрет на нескольких серверах» — обнаруживает и сигнализирует.
Ещё один практический сюжет, который заслуживает упоминания, — это nftables egress logging, который применён на серверах COSCIO. Большинство файрволлов настраиваются на блокировку входящего трафика и игнорируют исходящий. Логика проста: входящий — потенциальная атака, исходящий — наш собственный сервис работает. Но в современной модели угроз именно исходящий трафик становится ключевым индикатором компрометации. Если на сервере отчего-то начинаются исходящие соединения на 4444 порт неизвестного IP в Восточной Европе — это либо ваш ssh-туннель для разработчика, либо C2-канал зловреда. В первом случае соединение легитимное и должно быть в whitelist. Во втором случае — повод немедленно изолировать сервер от сети и расследовать. nftables egress logging пишет в журнал каждое исходящее соединение, не попадающее в whitelist; COSCIO эти записи парсит вместе с auth.log в рамках работы log analysis, и подозрительный исходящий трафик становится событием в общем потоке инцидентов. Это, опять же, не панацея — но один дополнительный слой видимости, который для xmrig-style атак работает безотказно: майнер обязан соединиться с пулом, иначе он бесполезен, и это соединение видно.
Отдельно стоит обсудить, что портал НЕ делает — потому что граница ответственности важна не меньше, чем сама ответственность. COSCIO не пишет код за разработчиков, не выбирает зависимости, не делает security-ревью pull request'ов. Если в репозиторий зальют код с SQL-инъекцией и она пройдёт в продакшн — портал её не обнаружит до тех пор, пока эта инъекция не будет проэксплуатирована и не оставит следов в логах. Для подобных задач существует SAST-инструментарий (Semgrep, CodeQL, Snyk Code), который интегрируется в CI и работает на этапе сборки. COSCIO ориентирован на runtime-фазу: серверы уже запущены, приложения уже работают, нужно следить за поверхностью атаки и реагировать. Разделение зон ответственности здесь намеренное: один продукт не может закрыть весь цикл безопасности без потери качества в каждой отдельной фазе. Лучше делать хорошо одну часть, чем плохо все.
Похожая граница проходит по WAF — Web Application Firewall. Это отдельный класс продуктов (Cloudflare WAF, ModSecurity, AWS WAF), которые анализируют HTTP-трафик и блокируют запросы с признаками атак на уровне приложения: попытки SQL-инъекций, XSS, path traversal, brute-force форм авторизации. COSCIO не WAF — он не сидит inline в http-потоке и не имеет возможности что-то заблокировать на этом уровне. Но COSCIO может интегрироваться с WAF через webhook: Cloudflare умеет отправлять события блокировок на внешний endpoint, и эти события попадают в COSCIO как инциденты. Получается тот же паттерн, что и с Wazuh: внешний специализированный инструмент делает свою работу, COSCIO агрегирует результаты в общую картину и предоставляет единый интерфейс для реагирования.
Заключительная мысль, которая, наверное, прозвучит банально, но в реальности повторяется снова и снова. Безопасность — это не продукт, а процесс. Установить COSCIO и считать вопрос закрытым нельзя — точно так же, как нельзя один раз обновить пакеты и считать сервер защищённым на всю жизнь. Портал даёт инструменты, расписание и видимость; дисциплина их применения остаётся на стороне команды. Открыть портал раз в день, посмотреть security score, разобраться с тремя жёлтыми пунктами, проверить, что инциденты за вчерашний день закрыты корректно — это пятнадцать минут. Не открывать неделю — это попадание в новости с заголовком про криптомайнер. Выбор обычно очевиден, и инструмент в данном случае нужен ровно для того, чтобы эти пятнадцать минут давали ту же отдачу, что раньше давал день ручной работы.
Тот инцидент с xmrig, который запомнился индустрии в 2026 году, в конечном счёте был обычной историей про неправильные дефолты и недостаточную видимость. PM2 startup под root — неправильный дефолт. Отсутствие мониторинга списка слушающих портов — недостаточная видимость. Отсутствие compliance-проверок на systemd-юниты — недостающий слой защиты. Каждая отдельная деталь — мелочь. Но именно из таких мелочей и складывается катастрофа, которая всплывает потом в виде криптомайнера, выжирающего CPU production-сервера в течение нескольких суток. Систем, которые ловят такие сочетания мелочей до того, как они становятся катастрофой, — недостаточно на рынке. Раздел Security в COSCIO — попытка построить одну из таких систем для аудитории, которой полноценный SOC недоступен, а наивный «авось» больше не работает.