Есть категория инцидентов, которые системные администраторы со стажем называют "тихими убийцами". Они не падают с грохотом, не вызывают шквала уведомлений, не светятся красным в Zabbix. Они подкрадываются медленно, не подают признаков жизни ровно до того момента, когда что-то перестаёт работать у клиента. Просроченный SSL-сертификат — классический представитель этого вида. Сервер жив, приложение отвечает, база данных работает, всё мониторится по CPU, RAM, диску и сетевым метрикам. А клиент в это время уже пять часов видит в браузере жирное предупреждение "Подключение не защищено" и уходит к конкурентам, не дочитав даже первый экран.
История, с которой стоит начать разговор, типична настолько, что повторяется в разных вариациях у любой компании, управляющей хотя бы десятком доменов. На одном из серверов когда-то был установлен certbot с автоматическим обновлением через systemd timer. В какой-то момент инженер мигрировал сервис с одного дистрибутива на другой, развернул всё через Docker, перенёс данные, проверил что приложение работает. И забыл, что certbot был установлен в систему как пакет, а после миграции в контейнер этот пакет остался, но больше не имеет доступа к новым путям конфигурации nginx. Timer срабатывает, certbot пытается обновить сертификат, получает ошибку, пишет её в журнал, тихо завершается. Никто этот журнал не читает. Через два с половиной месяца сертификат истекает в субботу вечером. До понедельника никто не обнаруживает проблему, потому что все внутренние мониторинги смотрят на доступность HTTP-эндпоинтов, а не на валидность TLS. В понедельник утром начинается шквал звонков от клиентов, инженер бежит к серверу, выясняет, что certbot давно сломан, восстанавливает renewal вручную, выпускает новый сертификат — и весь этот процесс занимает ещё час, потому что Let's Encrypt из-за многократных неудачных попыток на этом домене временно ушёл в rate-limit. Итого — пять-семь часов даунтайма, и это в лучшем случае, потому что часть клиентов уйдёт навсегда, не разбираясь, кто там виноват в красном окне браузера.
Такая история на полном серьёзе случается даже в крупных компаниях с зрелыми DevOps-практиками. Причина — в принципиальной слепоте традиционных систем мониторинга к этому классу проблем. Когда инженер настраивает Zabbix или Prometheus, он думает о метриках производительности и доступности. SSL — это не метрика, это атрибут. Сертификат либо валидный, либо нет, промежуточных состояний не бывает. Поэтому SSL обычно проверяется отдельным инструментом, отдельной командой, и часто этот инструмент живёт сам по себе, не интегрирован в общий поток алертов, а его настройка зависит от того, кто и когда его поднимал.
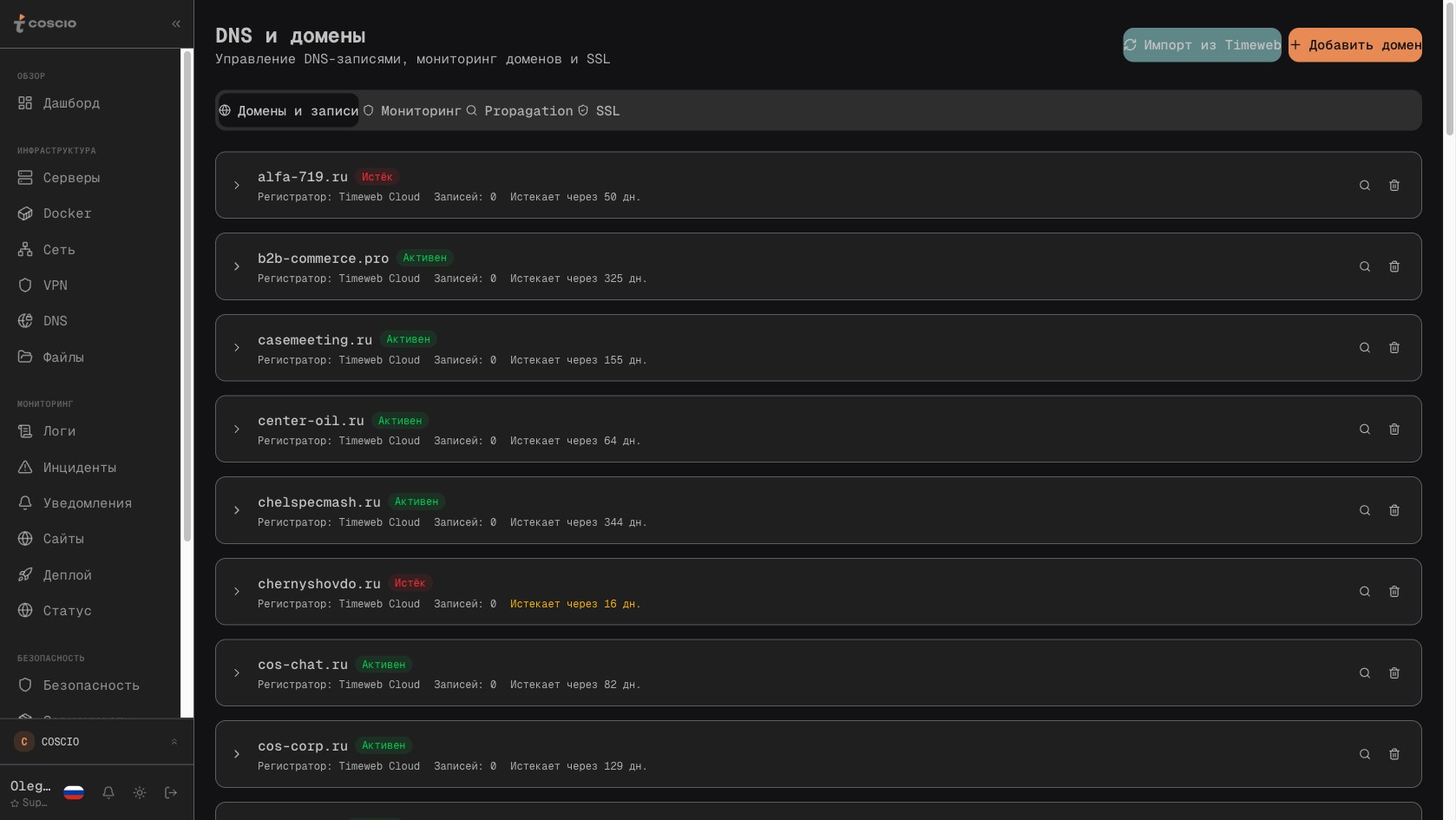
Раздел DNS и домены в COSCIO — реестр всех доменов компании с привязкой к серверам и сертификатам
Подход, который реализован в COSCIO, исходит из простой логики: если в одной системе уже есть реестр серверов, реестр доменов и реестр DNS-записей, то проверка SSL для каждого домена должна быть встроена туда же. Не отдельный сервис, не cron на каком-то bastion-сервере, не подписка на внешний UptimeRobot SSL Monitor, который надо вручную синхронизировать с реальным списком доменов. Один источник правды о том, какие домены вообще существуют у компании, и для каждого из них автоматическая ежедневная проверка состояния сертификата с алертом, если что-то не так.
Чтобы понять, почему именно интегрированный подход оказывается надёжнее, стоит разобрать альтернативы по очереди. Первый и самый распространённый вариант — bash-скрипт с openssl s_client в cron. Выглядит он примерно так: пишется обёртка, которая берёт список доменов из текстового файла, для каждого выполняет openssl s_client -connect domain:443, парсит вывод, извлекает дату окончания сертификата, сравнивает с текущей датой, и если осталось меньше N дней — шлёт письмо. Решение бесплатное, прозрачное, работает на любом сервере с openssl. И у него есть две принципиальные проблемы. Первая — список доменов в текстовом файле всегда отстаёт от реальности. Компания добавляет новый домен — никто не помнит про bash-скрипт на каком-то старом сервере мониторинга, добавить его туда забывают, новый домен выпадает из проверки. Вторая — алерт уходит на почту инженера, который этот скрипт когда-то писал, а этот инженер уже год как уволился. Письма продолжают приходить, но читать их некому. Скрипт работает, мониторинг есть, инцидент при этом всё равно случается.
Второй вариант — внешний коммерческий сервис типа UptimeRobot SSL Monitor, Pingdom, StatusCake или подобный. Здесь проблема смещается, но никуда не девается. Сервис нужно настроить, оплатить подписку, добавить в него все домены вручную. Каждый новый домен компании — это лишний клик в чужой админке, который кто-то должен сделать вовремя. Через год реестр доменов в Pingdom оказывается не похожим на реестр доменов в реальности, потому что половину забыли добавить, треть закрыли и забыли удалить, а ещё какая-то часть была добавлена с опечаткой и тихо проверяется на несуществующее имя. Дополнительно появляется ещё один источник алертов, который надо как-то склеивать с остальными уведомлениями — а у инженера и так уже четыре отдельные почтовые папки от разных систем.
Третий вариант — самописный сервис мониторинга. Здесь логика та же, что в первом, но завёрнутая в более красивую обёртку с базой данных, веб-интерфейсом, графиками. Часто такие сервисы рождаются как pet-проект инженера, который устал от первого варианта. Проблема в том, что это очередная отдельная система, которую надо хостить, поддерживать, обновлять, и которая всё равно содержит свой собственный список доменов, не связанный с реестром в CMDB или ITSM.
COSCIO решает эту задачу через объединение трёх вещей в одном месте: реестра доменов, реестра серверов и регулярной проверки SSL для каждой записи в реестре. В системе уже есть таблица доменов, к каждому домену привязан сервер, на котором он крутится. Когда инженер добавляет новый домен в систему — это обычная часть workflow по запуску любого нового сервиса. Без этого шага домен не попадает в мониторинг сайтов, не попадает в DNS-управление, не попадает в Public Status Page, не попадает в инвентаризацию для compliance-отчёта. Один и тот же реестр кормит все эти модули. И SSL-мониторинг — естественная часть того же конвейера.
Мониторинг сайтов — периодические HTTP/HTTPS проверки со статусом SSL
Технически проверка устроена так. В COSCIO есть отдельная BullMQ-очередь под названием ssl. Это часть общей инфраструктуры фоновых задач — в системе 19 разных очередей, каждая под свой класс работ: метрики серверов, логи, докер-хелсчеки, бэкапы, DNS, VPN, и так далее. Очередь ssl получает регулярную задачу через scheduler — раз в сутки, в час, который настраивается администратором в разделе Settings → Platform → Scheduler. По умолчанию это пять утра по серверному времени, но любая команда может сдвинуть на удобный для себя час. Задача проходит по всем доменам в реестре текущего рабочего пространства и для каждого выполняет одно и то же: устанавливает TCP-соединение на порт 443, проводит TLS-handshake, извлекает из ответа сервера сертификат в формате X.509, парсит его, достаёт три ключевых поля — дата начала действия, дата окончания, эмитент. Дополнительно вычисляется fingerprint, чтобы можно было отслеживать факт смены сертификата (новый отпечаток при том же домене — значит, renewal произошёл).
Полученные данные складываются в таблицу SslCertificate. Это upsert — если запись для этого домена уже есть, она обновляется, если нет — создаётся. Никакой истории изменений в самой таблице нет, но факт обновления fingerprint остаётся в логах системы, и при желании можно посмотреть, когда именно сертификат был обновлён в последний раз. Дальше идёт логика принятия решений на основе срока действия. Если до даты окончания осталось больше 30 дней — никаких действий, просто запись обновлена. Если осталось меньше 30 дней, но больше 7 — система помечает этот сертификат как требующий внимания и добавляет в дайджест AI-инсайтов, который выводится на главном дашборде. Если осталось меньше 7 дней — это уже critical, и тут запускается полноценная цепочка алертов: создаётся уведомление в системе, рассылается через все подключенные каналы (Email, Telegram, SMS, in-app SSE), и создаётся открытый инцидент с привязкой к серверу. Если дата окончания уже в прошлом — инцидент создаётся с высшим приоритетом, плюс на Public Status Page (если он включён) появляется отметка о проблеме с этим сервисом.
Важный архитектурный момент — система не дублирует инциденты. Если для одного и того же домена уже открыт инцидент по причине истекающего SSL, новый при следующей проверке не создаётся. Существующий обновляется новыми данными — сколько часов осталось, какой fingerprint, последняя успешная проверка. Это спасает от ситуации, когда сертификат истёк, никто его не обновил пять дней, и за это время накопилось 120 одинаковых уведомлений в Telegram. Один инцидент, несколько обновлений в нём, понятная история — этого достаточно.
Статус систем — общий обзор здоровья инфраструктуры включая SSL-сертификаты
Отдельного разговора заслуживает решение о частоте проверок. На первый взгляд кажется, что чем чаще, тем лучше — каждый час, каждые десять минут, постоянно держать руку на пульсе. На практике это плохая идея по нескольким причинам. Первая — SSL-сертификаты в принципе меняются редко. Let's Encrypt выдаёт сертификаты на три месяца, коммерческие — обычно на год. Между двумя изменениями реально что-то проверять имеет смысл раз в сутки, иначе все промежуточные проверки покажут идентичный результат и не дадут никакой новой информации. Вторая причина — у Let's Encrypt и у любого крупного издателя сертификатов есть rate-limits. Если на одном домене внезапно начнут случаться сотни TLS-handshake в день не от реальных пользователей, а от внутреннего мониторинга, это может насторожить балансировщики, повлиять на CDN-метрики, в худшем случае попасть в чёрные списки. Третья — это просто нагрузка на собственные серверы, ненужная, потому что результат тот же самый. Поэтому ssl queue в COSCIO работает раз в сутки, и для большинства инфраструктур этого хватает с огромным запасом. Если у компании какие-то особенные требования по compliance (например, нужно подтверждать состояние сертификатов чаще для аудитора), частоту можно повысить в настройках, но это редкий случай.
Принципиальное отличие подхода COSCIO от классических SSL-мониторов в том, что система намеренно не пытается обновлять сертификаты сама. Это решение, которое многим инженерам сначала кажется странным — раз уж платформа всё знает про сертификаты, почему бы не дёрнуть certbot за неё в нужный момент. Причин не делать этого несколько. Главная — на серверах уже работает certbot со своим systemd timer, который обновляет сертификаты автоматически за тридцать дней до истечения. Если COSCIO начнёт делать то же самое параллельно, возникнет дублирование запросов, и оба клиента могут одновременно пытаться обновить один сертификат. Let's Encrypt не любит такого поведения и накладывает rate-limits. В худшем случае оба запроса завершатся неудачей, и сертификат, который должен был обновиться без проблем, не обновится вообще. Вторая причина — certbot уже знает локальную специфику сервера: какие пути у конфигов nginx или apache, какие plugin использовать, какие хуки запускать после renewal. Дублировать всю эту логику внутри COSCIO значило бы переписывать половину функционала certbot для всех возможных конфигураций, что бессмысленно. Третья — это вопрос ответственности. Если COSCIO начнёт сам трогать сертификаты, это размывает границу между мониторингом и активным управлением. Лучше, когда мониторинг честно говорит "вот тут проблема", а решение принимает человек или отдельная автоматизация, специально для этого настроенная.
В результате роль COSCIO в жизненном цикле SSL-сертификата получается чёткой и ограниченной: заметить, что что-то идёт не так. Если certbot работает нормально, COSCIO видит, как каждые два месяца обновляется fingerprint сертификата, и не делает ничего. Если certbot сломался — а сломаться он может по самым разным причинам, от закончившегося места на диске до изменений в логике плагина после апгрейда системы — COSCIO замечает это за 30 дней до истечения и кричит. У инженера есть месяц, чтобы починить renewal без всяких авралов. Это принципиально другая ситуация по сравнению с историей из начала статьи, где о проблеме узнают в понедельник утром по звонкам клиентов.
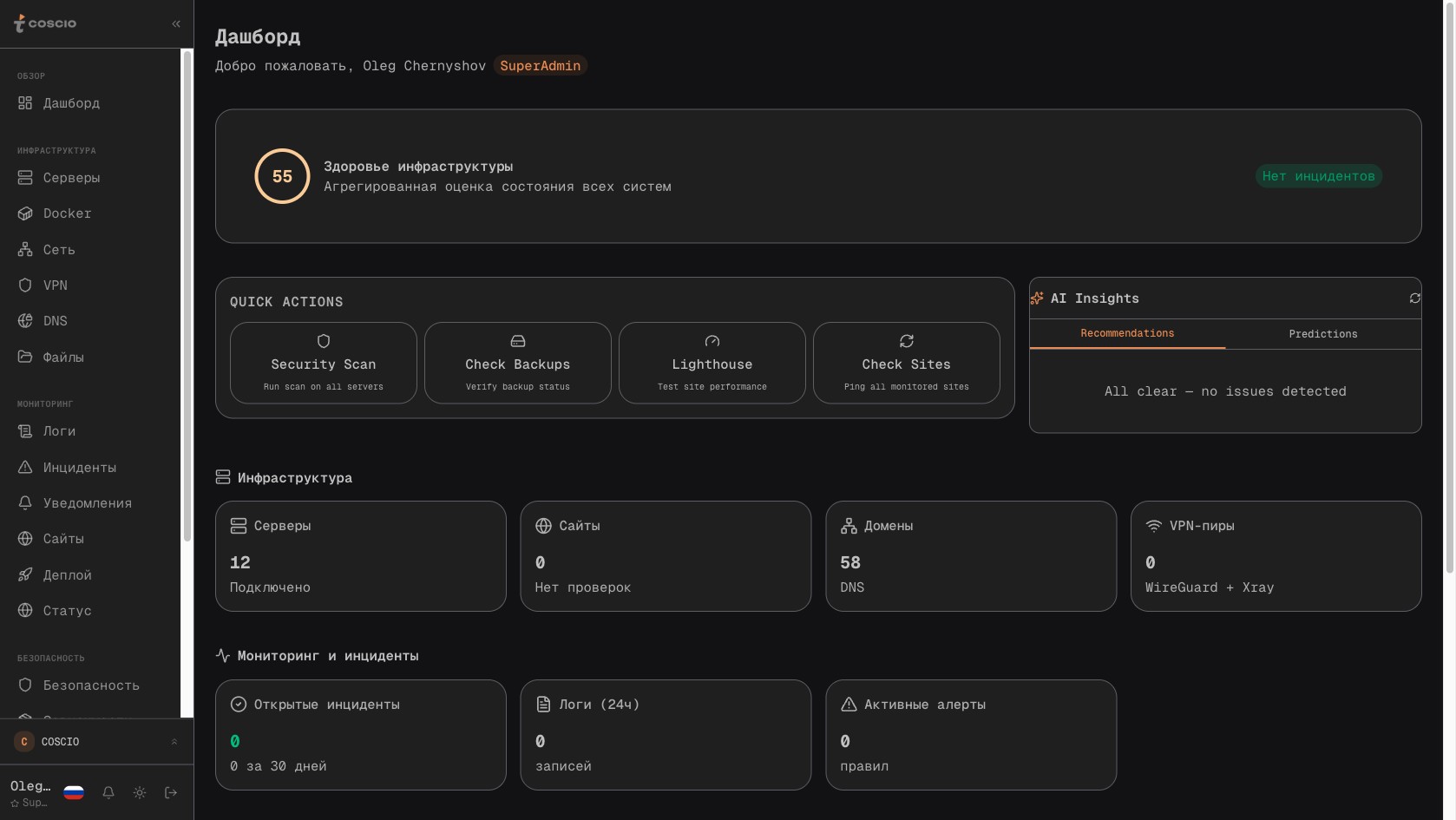
Дашборд COSCIO с панелью AI-инсайтов, включая блок SSL expiring
Отдельная история — мониторинг SSL для разных типов сертификатов и разных конфигураций. Системе принципиально всё равно, кто эмитент. Let's Encrypt с его тремя месяцами, коммерческий Sectigo на год, дорогой EV-сертификат от Digicert на два года — все они одинаково проверяются через стандартный TLS-handshake, у всех в X.509 одинаковые поля Not Before и Not After. COSCIO не зависит от API конкретного издателя сертификатов, потому что использует свойство SSL как протокола — любой валидный сертификат при handshake показывает свой срок действия, и этого достаточно для мониторинга. Это работает и для wildcard-сертификатов, и для multi-SAN, где один сертификат покрывает десяток доменов. В реестре доменов каждый домен числится отдельно, при проверке система видит, что сертификат покрывает несколько имён, и обновляет записи для всех соответствующих доменов с одинаковыми датами и fingerprint. Если у компании есть один wildcard *.example.com и десять субдоменов в реестре, проверка по любому из них даёт информацию для всех десяти.
Интересный случай — когда домен через DNS-запись CNAME уходит на CDN или другой внешний сервис. Например, www.company.ru указывает на cdn-edge.cloudfront.net, и реальный TLS-handshake с пользователем происходит у CDN, а не у origin-сервера компании. В этой ситуации проверка SSL у origin даст один сертификат (тот, который компания установила сама), а пользователь в браузере увидит другой (тот, который CDN предоставил для своей edge-точки). Для пользователя важен второй, а не первый. COSCIO позволяет в реестре доменов указать "проверочную точку" — то есть имя хоста, через которое нужно делать TLS-handshake. По умолчанию это сам домен, но если задано отдельное значение, проверка пойдёт именно туда. Так система может корректно мониторить SSL у CDN-провайдера, не путаясь с тем, что origin-сервер показывает совсем другой сертификат.
Параллельно с проверкой срока действия в той же таблице сохраняется issuer — кто выпустил сертификат. Это даёт возможность построить простую инвентаризацию: на скольких серверах у компании Let's Encrypt, на скольких коммерческие сертификаты, какой издатель сколько процентов покрывает. Для compliance-отчётов это важная информация, потому что некоторые регуляторы требуют использовать определённых издателей. Для финансового учёта тоже полезно — если компания тратит деньги на коммерческие сертификаты, удобно видеть общую картину: какие домены покрыты Let's Encrypt (бесплатно), какие требуют годового продления коммерческого сертификата, когда у каждого следующий renewal, какой бюджет на это нужен. В большинстве компаний эта информация разбросана по почтам разных инженеров, накладным от разных вендоров, и собрать её к концу года в один отчёт стоит человеко-дня работы. Когда всё лежит в одной таблице с фильтрами и сортировкой, отчёт делается за пять минут.
Возвращаясь к сценарию из начала статьи — как бы он развивался при включённом мониторинге через COSCIO. Инженер мигрирует сервис в Docker, certbot пакетный остаётся в системе, но больше не имеет доступа к нужным путям. Сертификат истекает через два с половиной месяца. За 30 дней до истечения система при ежедневной проверке видит, что fingerprint сертификата не обновился (хотя должен был) и срок действия меньше порога. На утреннем дашборде в блоке AI-инсайтов появляется уведомление: "SSL expiring on api.company.ru in 28 days, last renewal 67 days ago". Инженер видит это в первой же утренней проверке. У него четыре недели на разбор ситуации. Он понимает, что certbot не отработал, проверяет логи, находит проблему с путями, либо переносит renewal в новый контейнер, либо настраивает certbot заново. Сертификат обновляется, при следующей проверке fingerprint меняется, дата окончания снова в норме, инсайт со страницы дашборда уходит. Никакого даунтайма, никаких звонков от клиентов, ни одного потерянного посетителя. Стоимость такого результата — десять минут настройки нового домена в реестре COSCIO в момент его создания и три секунды ежедневной автоматической проверки.
Раздел Инциденты — открытые проблемы инфраструктуры с привязкой к источнику, включая SSL
Стоит подробнее остановиться на блоке AI-инсайтов на главном дашборде, потому что это одно из мест, где SSL-мониторинг встраивается в более широкую картину. AiInsightsPanel — это компонент, который агрегирует разнородные сигналы со всех модулей платформы и выводит на главный экран то, что требует внимания именно сегодня. Туда попадают открытые инциденты, проваленные бэкапы, обнаруженные CVE в зависимостях, неожиданные всплески расходов на облачных провайдерах, и в том числе истекающие SSL-сертификаты. Логика проста: утро инженера или директора по IT начинается с этой панели, и в идеале на ней либо пусто (всё хорошо), либо есть пара-тройка пунктов с понятной приоритезацией. SSL expiring в этом списке появляется за месяц до проблемы и остаётся на дашборде, пока ситуация не разрешится. Это намеренно — даже если первое утро инженер пропустил инсайт, он увидит его на второе утро, на третье, и так далее. В отличие от единичного email-уведомления, которое можно проглядеть и потерять в почте, постоянное присутствие на главном экране заметно надёжнее.
Тот же сигнал параллельно идёт в персональные каналы уведомлений каждого пользователя, у которого включены такие уведомления. У каждого участника рабочего пространства в COSCIO есть настройки — какие классы событий он хочет получать и через какие каналы. SSL warnings обычно подписаны на инженеров и тимлидов, кто-то получает их в Telegram, кто-то предпочитает email, кому-то приходит SMS если событие критическое. SSE-канал в браузере показывает уведомление в реальном времени, если человек как раз сидит в портале. Один источник события, гибкая маршрутизация по каналам, без необходимости настраивать пять разных систем оповещения.
Полезное свойство интеграции — связь SSL-мониторинга с инцидент-менеджментом и Public Status Page. Если сертификат истёк и при следующей проверке система это зафиксировала, автоматически создаётся инцидент в общем модуле инцидентов. У этого инцидента есть тип (ssl_expired), привязка к серверу, к домену, статус, время начала, ответственный (если назначен). На внешней Status Page, если она у компании включена и этот сервис на ней присутствует, появляется отметка о проблеме. Клиенты, которые наблюдают за статусом, сразу видят, что у компании есть осведомлённость о проблеме и она в работе. Это снижает шквал звонков в поддержку — половина клиентов просто проверит статус-страницу перед тем, как звонить. После того как сертификат обновлён и проверка показала валидную дату действия, инцидент автоматически закрывается, на статус-странице сервис снова отмечен зелёным. История инцидента сохраняется для пост-мортем анализа: что именно случилось, сколько длилось, какой был root cause.
Один из неочевидных эффектов от наличия такого мониторинга — снижение количества "тёмных доменов". В крупных компаниях с историей в несколько лет всегда есть домены, про которые забыли. Маркетинг как-то делал лендинг для прошлогодней кампании, домен зарегистрирован, сайт развёрнут, кампания закончилась — лендинг живёт сам по себе. Никто не помнит про него, домен продлевается автоматически с корпоративной карты, certbot работает или не работает — никто не проверяет. Через два года кто-то находит этот домен в гугле, идёт по ссылке, видит "Not secure" — и это удар по бренду, потому что выглядит как заброшенность. Когда в COSCIO ведётся реестр всех доменов компании, включая такие "забытые" лендинги, мониторинг работает и для них. Сертификат начинает истекать — кто-то видит это в инсайтах, может принять решение: либо обновлять сертификат и поддерживать, либо признать домен ненужным и снять с обслуживания. Без мониторинга такие решения не принимаются вовремя, потому что про сам факт существования домена все забыли.
Есть и обратная польза — иногда мониторинг показывает, что сертификат, который должен быть, отсутствует. Это случается, когда инженер развернул новый сервис, добавил его в реестр доменов, но забыл настроить certbot. При первой проверке система не сможет установить TLS-handshake вообще, или установит, но получит самоподписанный сертификат, или сертификат для другого домена (которому случайно проксируется запрос). Все эти ситуации фиксируются как ошибки проверки и тоже попадают в алерты. Лучше узнать о проблеме на следующее утро после деплоя, чем через месяц от клиентов.
Технически вся эта система устроена на стандартных компонентах. BullMQ как очередь задач — это давно зрелое решение для Node.js-приложений, основанное на Redis. Очередь ssl ничем принципиально не отличается от других девятнадцати очередей в системе, она использует тот же механизм repeatable jobs со скеджулером. SslService, который реализует логику проверки, состоит из нескольких сотен строк кода: установка соединения через стандартный модуль tls в Node.js, парсинг сертификата, сохранение в Prisma. Никаких внешних зависимостей от облачных API, никаких подписок, никаких отдельных систем. Это важный архитектурный принцип — мониторинг SSL должен работать локально, не требуя внешних запросов к каким-то платным провайдерам, потому что иначе SSL-мониторинг становится критическим компонентом, зависящим от внешней доступности, а это лишний риск.
Стоит сказать пару слов про производительность. На инфраструктуре из ста доменов проверка занимает порядка трёх-четырёх минут — каждый handshake выполняется за несколько секунд, проверки идут с небольшим параллелизмом, чтобы не нагружать сеть и не давать burst-нагрузку. На тысяче доменов проверка займёт минут двадцать-тридцать. Это совершенно неощутимо в рамках суточного цикла, и для большинства компаний с десятками-сотнями доменов задача укладывается в считанные минуты. Для случая крупного хостинг-провайдера с десятками тысяч доменов потребовалось бы пересмотреть архитектуру — разбить проверку на несколько worker-процессов, шардировать домены, возможно, делать проверку не строго раз в сутки, а распределить во времени равномерно. Но для типичной инфраструктуры IT-департамента средней компании всё работает без танцев с бубном.
Возникает закономерный вопрос: что насчёт сертификатов на внутренних сервисах, которые недоступны извне? Например, у компании есть внутренний портал admin.internal.company.ru, который существует только в LAN или за VPN. С точки зрения публичного интернета этот хост недоступен, но у него тоже есть SSL-сертификат, и он тоже может истечь. COSCIO решает это через привязку проверочной точки — если в реестре домена указан внутренний IP-адрес или хост, проверка пойдёт от worker'а, у которого есть сетевой доступ. Поскольку платформа работает на сервере внутри корпоративной сети (или имеет VPN-туннель в неё), такие домены тоже проверяются нормально. Внешний SSL-мониторинг типа UptimeRobot этого не умеет в принципе — у него нет доступа к внутренней сети клиента.
Отдельная история — Public Status Page. Это публичная страница, которую компания может выставить наружу для информирования клиентов о статусе своих сервисов. На статус-странице показывается состояние ключевых сервисов: основной сайт, API, личный кабинет, и так далее. Для каждого сервиса можно настроить набор проверок: HTTP-доступность, SSL-валидность, и так далее. Если какая-то из проверок не проходит, сервис отмечается жёлтым (degraded) или красным (down). Когда сертификат у домена истекает, на статус-странице соответствующий сервис автоматически перейдёт в degraded. Это даёт клиентам возможность самостоятельно проверить, есть ли проблема, прежде чем звонить в поддержку. И это снова та же логика — единый источник правды о состоянии инфраструктуры, и SSL-проверки естественно интегрированы в общий статус, а не существуют отдельно.
Стоит ещё раз вернуться к тому, почему встроенный мониторинг оказывается принципиально надёжнее внешних аналогов. Причина не в технической сложности — повторить логику ежедневного TLS-handshake может любой инженер за пару часов. Причина в синхронизации между реестром реальных доменов компании и списком проверяемых объектов. Когда эти две сущности разные — обязательно появится дрейф. Сегодня всё совпадает, через полгода в одном списке пятнадцать доменов, в другом восемнадцать, через год расхождение становится уже неуправляемым, и кто-то получает звонок от клиента про красный замочек на сайте, про который все думали, что он закрыт ещё в прошлом году. Когда же эти сущности — одно и то же, синхронизация поддерживается автоматически просто фактом того, что нет двух мест для ведения списка.
И последний штрих к картине — собирать все эти сигналы в одно место утром понедельника, перед началом рабочей недели. Когда руководитель IT-департамента или дежурный инженер открывает COSCIO и видит на дашборде агрегированный AI-инсайт со списком пунктов "что требует внимания в ближайшие тридцать дней" — там вперемешку висят истекающие SSL, увеличившиеся расходы на облако, обнаруженные за выходные CVE в зависимостях, проваленный бэкап на одном из второстепенных серверов. Это позволяет за десять минут утром понимать, что в инфраструктуре идёт не по плану, и распределять задачи команды на неделю исходя из реальной картины, а не из вчерашних эмоций. SSL-мониторинг становится не отдельным громко-кричащим сервисом, а одним из голосов в хоре, который звучит фоном и привлекает внимание только тогда, когда есть к чему. Именно такая работа и нужна от инфраструктурного мониторинга в зрелой компании — не суета, не алерт-шторм, а спокойное и надёжное информирование с упреждением.
Сам по себе SSL-сертификат остаётся одной из самых тривиальных частей инфраструктуры. Установить, обновить, проверить дату — всё это не требует никакой космической экспертизы. Драма всегда происходит на стыке: между моментом, когда что-то ломается, и моментом, когда об этом узнают. Сократить этот зазор с нескольких дней или недель до нескольких часов — задача мониторинга. А встроить мониторинг SSL в общую систему управления инфраструктурой, чтобы он работал без отдельной настройки для каждого нового домена и без отдельной системы алертов — задача единого портала, такого как COSCIO. Когда такое решение работает правильно, истории про "сертификат истёк в выходные, никто не заметил, потеряли клиентов в понедельник" уходят в прошлое. Не потому что сертификаты перестают истекать — они истекают как и раньше. А потому что у инфраструктурной команды есть тридцать дней спокойного предупреждения вместо пяти часов хаоса по факту.